10. アノテーション
特定のデータ値の明示的なラベル付けと注釈付けは、多くの場合、データの可視化と分析において重要な要素です。ParaViewには、レンダリングで注釈を付けるためのさまざまなメカニズムが用意されており、レンダービュー内の他の視覚要素と一緒にレンダリングされたフリーの浮動テキストから、特定の点またはセルに関連付けられたデータ値まであります。
10.1. アノテーションソース
いくつかのタイプのテキスト注釈 (アノテーション、Annotation)は、Sources > Alphabetical メニューから追加できます。これらのソースからのテキストは、レンダリングビューの3D要素の上に描画されます。すべての注釈ソースは、 Properties パネルの Display セクションでいくつかの共通プロパティを共有します。これには、使用するフォント、テキストのサイズ、色、不透明度、位置合わせなどの Font Properties や、太字、斜体、影付きなどの適用するテキスト効果が含まれます。

図 10.1 アノテーションソースおよびフィルタのフォントプロパティコントロール
ParaView では、Arial、Courier、Timesの3種類のフォントを使用できます。 また、ポップアップメニューの Font Properties の下の File エントリを選択し、フォントファイルテキストフィールドの右にある ... ボタンをクリックして、任意のTrueTypeフォントファイル(*.ttf)を指定することもできます。ファイル選択ダイアログが表示され、paraview (又は pvpython )が実行されているファイルシステムからフォントファイルを選択できます。
残りの表示プロパティは、テキストをレンダービューのどこに配置するかをコントロールします。配置モードには、レンダービューに対する定義済みの位置を使用するモードと、レンダービューでの任意のインタラクティブな配置を可能にするモードの2つがあります。最初のモードは、 Use Window Location チェックボックスが選択されている場合にアクティブになります。これにより、注釈をレンダービューの4つのコーナーのいずれかに配置したり、レンダービューの上部または下部の水平方向の中央に配置することができます。位置を表すアイコン付きのボタンが Pipeline ブラウザに表示されます。これらのボタンは、図 10.2 に示すように、レンダービュー内の位置に対応します。
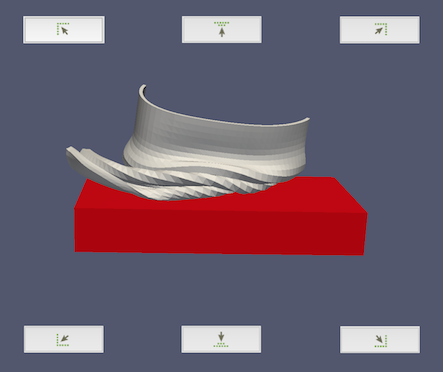
図 10.2 アノテーション配置ボタンとアノテーションを配置する場所
2番目のモードは Lower Left Corner チェックボックスをクリックするとアクティブになり、注釈を自由に配置できます。 Interactivity プロパティが有効な場合は、レンダービューで注釈をクリックしてドラッグして配置するか、注釈の境界ボックスの左下コーナーを配置する位置を手動で入力できます。座標は、x次元とy次元の[0, 1]からの範囲の分数座標で定義されます。レンダービューの座標系の原点は左下であるため、 Lower Left Corner の値[0、0]を指定すると、注釈はレンダービューの左下コーナーに配置されます。
10.1.1. Text ソース
Text ソースを使用すると、レンダービューにテキスト注釈を追加できます。表示されるテキストを定義するプロパティが1つあります。テキストは複数行にすることができ、数字とUnicode文字を含めることができます。また、開始と終了のドル記号の間にMathtex式を含めることもできます。数式は、TeXの数式 [dt] のサブセットです。Mathtextを使用する場合、テキストは1行のみにすることができます。
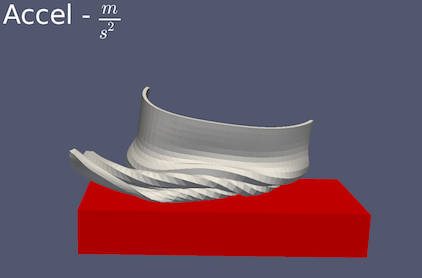
図 10.3 Mathtext [dt] 式からレンダリングされた数式を使用した、左上隅にある Text ソース・アノテーションの例
10.1.2. Annotate Time ソース
Annotate Time ソースは Text ソースとほぼ同じですが、ParaViewに設定されている現在の時刻の値にもアクセスすることができます。時刻の表示形式は Format プロパティで制御することができます。このプロパティには、fmt ライブラリで理解できるオプションのフォーマットセクションを含む文字列を指定します。デフォルトでは、"Time: {time:f}"となり、中括弧内の "time "はParaViewの現在の時刻に置き換えられ、":f "は小数点以下6桁の浮動小数点としてフォーマットされることが指定されます。その他のフォーマットについては、https://fmt.dev/latest/syntax.html にある fmt のシンタックスの説明を参照してください。例題はそのページの一番下にあります。
10.2. アノテーションフィルタ
前節で説明したアノテーションソースは、読み込まれたデータセットに依存しないテキストアノテーションを追加するために利用できます。パイプラインブラウザで利用可能なデータソースの値を表示するアノテーションを作成するために、いくつかのアノテーションフィルタが利用可能です。テキストフォントやアノテーションの場所を変更するためのプロパティは、前のセクションで説明したアノテーションソースで利用できるものと全く同じです。
10.2.1. Annotate Attribute Data フィルタ
Annotate Attribute Data を使用すると、データセット内の配列(または属性)からのデータ値を使用して注釈を作成できます。フィルタを使用するには、まず Select Input Array で目的のデータを含むデータ配列を選択します。これらの配列は、点、セル、またはフィールドのデータ配列です。 Element Id プロパティは、注釈に値を表示する点またはセルのインデックスを指定します。選択した入力配列がフィールド配列(点またはセルに関連付けられていない)の場合、 Element Id は表示する配列のタプルを指定します。並列に実行している場合、 Process Id は値を取得する配列を保持しているプロセスを表します。
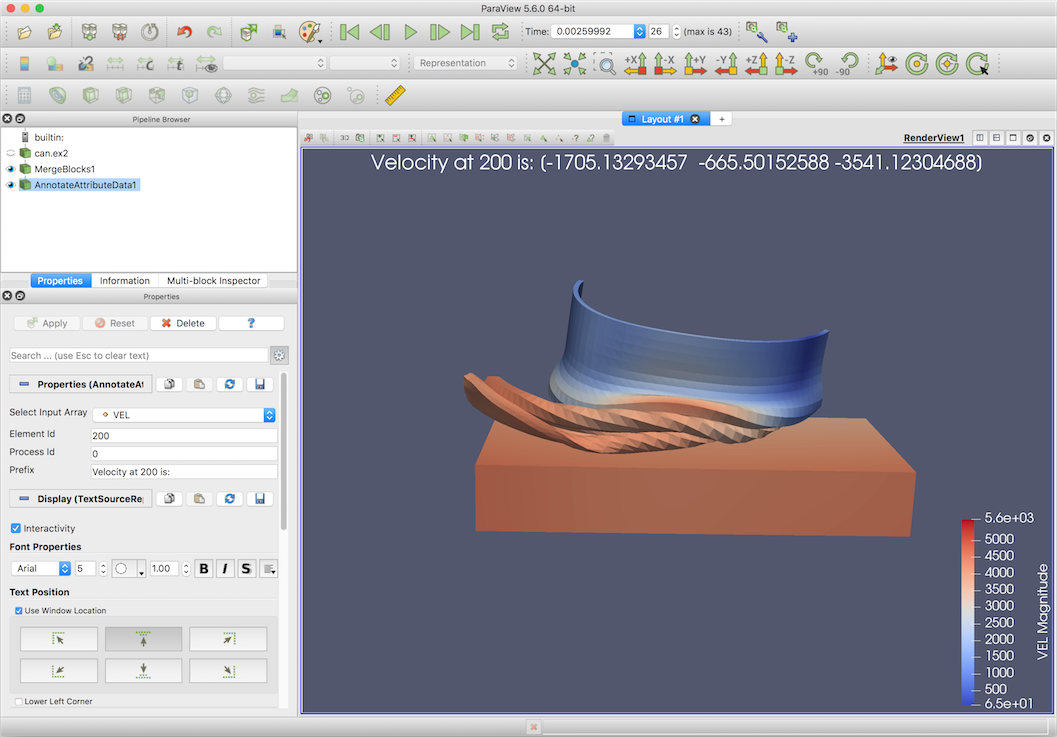
図 10.4 Annotate Attribute Data フィルタのプロパティ
Prefix テキストプロパティは、レンダリングされた注釈の属性値の前に配置されます。書式設定文字列がありません。接頭辞の後に番号が追加されます。選択した配列値がスカラー値の場合、注釈には数値のみが含まれます。一方、配列の値がマルチコンポーネント配列の場合、個々のコンポーネントは括弧で囲まれたスペース区切りのリストで注釈ラベルに追加されます。
10.2.2. Annotate Global Data フィルタ
ファイルフォーマットによっては、タイムステップごとにデータ配列に格納される単一のデータ値である global data` という概念を含むものもあります。ParaView はこのようなデータ値のセットを、タイムステップと同じ数の値を持つデータセットに関連付けられたフィールドデータ配列として保存します。レンダリングビューにこれらのグローバルな値を表示するには、Annotate Global Data フィルタを使用します。配列選択 Select Arrays ポップアップメニューには、利用可能なフィールドデータ配列が表示されます。Prefix と Suffix プロパティは、それぞれアノテーション内のデータ値の前と後にきます。Format プロパティは、 printf 関数呼び出しで使用するような、C 言語の数値フォーマット指定子です。このフォーマットが global data 型に対して無効な場合は、フィルタが警告を表示します。
10.2.3. Annotate Time Filter フィルタ
ParaView の優れた機能は、異なる時刻に異なるデータを生成するデータソースをサポートすることです。たとえば、要求されたタイムステップのデータを読み込むファイルリーダーや、特定の時間フィルタなどがあります。各データソースは、データを生成できる時間値を ParaView に伝達します。ParaViewで生成および表示されるデータは、ParaView VCR Controls または Time Inspector パネルで設定した時間によって異なります。
さらに素晴らしいのは、複数のデータソースを持ち、それぞれが情報を出して、おそらく固有の時間のセットに応答できることです。つまり、利用可能なソースは、同じ時点のセットをサポートしていることを伝達する必要はありません。実際、まったく異なる時点でデータを定義することがあります。要求された時間が与えられると、各データソースは、要求された時間に最も近いサポート時間に対応するデータを生成します。この機能により、たとえば、異なる時間解像度で変化する複数のデータセットからアニメーションを作成できます。
前述の Annotate Time ソースは ParaView が現在要求している時間を表示するために使用できますが、特定のデータソースが応答している時間値を表示するわけではありません。例えば、ParaView は時間5.0のデータを要求しているかもしれませんが、ソースが時間値10.0以上のデータを生成する場合、時間5.0が要求されていても、時間10.0のデータを生産データソースがデータを生成している時間を表示するには、代わりに Annotate Time Filter を使用することができます。このフィルタを目的のデータソースにアタッチするだけです。複数のデータソースが存在する場合、このフィルタの個別のインスタンスをそれぞれのデータソースにアタッチすることができます。
時刻の表示形式は Format プロパティで制御することができます。このフォーマット文字列は fmt ライブラリでサポートされている文字列で、デフォルトは "Time: {time:f}" です。中括弧内の "time" は、このフィルタが接続されているデータソースの現在ロードされている時刻の値に置き換えられます。このフィルタには Shift と Scale プロパティも含まれており、表示される時刻を線形に変換するために使用されます。時間の値にはまずスケールが掛けられ、次にシフトが加えられます。
10.2.4. Environment Annotation フィルタ
可視化が生成された環境に関する情報を表示する場合は、 Environment Annotation フィルタを使用します。このフィルタをデータソースにアタッチすると、ParaView を実行しているシステム上のユーザ名を自動的に表示したり、ユーザ名の生成に使用されたオペレーティングシステムを表示したり、ビジュアル化が生成された日時を表示したり、ソースデータのファイル名を表示することができます(該当する場合)。これらの各項目は、このフィルタの Properties パネルのチェックボックスで有効または無効にできます。
このフィルタの入力ソースがファイルリーダの場合、 File Name プロパティはファイル名に初期化されます。ファイルのフルパスを表示するには、 Display Full Path チェックボックスを使用できますが、オフにした場合はファイル名のみが表示されます。このデフォルトのファイルパスは、 File Name プロパティのテキストを変更することでオーバーライドできます。このフィルタがリーダーではなくフィルタにアタッチされている場合、ファイルパスは空の文字列に初期化されます。元のファイル名に手動で変更することも、必要に応じて任意の文字列に変更することもできます。
10.2.5. Python Annotation フィルタ
最も汎用性の高い注釈フィルタである Python Annotation フィルタは、データセットに関する情報を含む注釈を生成する最も一般的な方法を提供します。点、セル、フィールド、および行のデータ配列から値にアクセスし、 Expression プロパティで定義された短いPython式の算術演算と組み合わせることができます。 Expression で使用可能なデータ配列のタイプは、 Array Association プロパティで設定されます。
先に進む前に、 Python Annotation フィルタの使用例を見てみましょう。点インデックス22の Pressure という名前の点配列のデータ値を表示するとします。まず、 Array Association を Point Data に設定して、点データ配列がPythonの注釈式で参照できるようにします。点22の圧力値を表示するには、 Expression プロパティを次のように設定します。
Pressure[22]
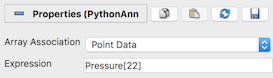
図 10.5 点22の Pressure 配列の値を示している、基本的な Python Annotation フィルタの例
Pythonの式を拡張して、注釈により多くの意味を持たせることができます。プレフィックスを追加するには、 Expression を次のように設定します。
'Pressure: %f' % (Pressure[22])
noindent 選択した関連付けのすべてのデータ配列は、名前が有効なPython変数である限り、式で参照できる変数として提供されます。無効なPython変数名である配列名は、配列名を修正して使用できます。この配列名のサニタイズされたバージョンは、文字、数字、アンダースコア (_) である配列名の文字のサブセットが、元の配列名に現れる順にスペースなしで結合されたものです。たとえば、Velocity X という名前の配列は、変数 VelocityX で使用できます。
マルチブロックデータセットなどの複合データセット内の点データおよびセルデータへのアクセスは、非複合データセット内の点データまたはセルデータへのアクセスとは多少異なります。 式
Pressure[22]
は、非複合データセット内の点配列から単一のスカラー値を取得し、同じ式は各ブロック内の Pressure 配列の22番目の要素を取得します。これらの値は、データセット内の各ブロックに関連付けられた配列を保持するデータ構造であるVTKCompositeDataArrayに保持されます。 したがって、次の式
Pressure[22]
は複合データセット上で評価され、返されて表示される値は、実際には各ブロックからの配列値の集合です。単一のブロックから値にアクセスするには、そのブロックの配列を、結果VTKCompositeDataArrayの Arrays メンバから選択する必要があります。たとえば、ブロック2の22番目の点に関連付けられた Pressure 値を表示するには以下のようになります。
Pressure[22].Arrays[2]
この式は、 Pressure 配列が単一のコンポーネントを持つと仮定して、レンダリングされた注釈に単一のデータ値を生成します。配列の値の範囲を表示するには、インデックスの Pressure フィールドでPythonの範囲式を使用します。例えば、以下のようになります。
Pressure[22:24].Arrays[2]
これにより、ブロック2の点22と23の Pressure 値が表示されます。また、Arrays メンバにインデックス範囲を指定して、複数の配列を取得することもできます。例えば、以下のようになります。
Pressure[22:24].Arrays[2:5]
この式は、ブロック2、3、および4の点22および23に対して Pressure と評価されます。
Array Association は、指定した関連付けのデータ配列のセットを、 Expression で使用できる変数として使用できるようにするための便利な機能です。これらの配列名を使用する欠点は、一度に1つの配列の関連付けしか使用できないことです。つまり、たとえば、セルデータ配列と点データ配列の組み合わせを必要とする注釈は、これらの便利なPython変数だけでは表現できません。
幸いなことに、少し冗長な式を使用すると、このフィルタの入力内の任意の配列にアクセスできます。たとえば、次の式は、セルのデータ値に点のデータ値を乗算します。
inputs[0].CellData['Volume'][0] * inputs[0].PointData['Pressure'][0]
上記の例では、入力内の配列は元の配列名を使用してアクセスされることに注意してください。
上記の例では、式 inputs[0] はフィルタへの最初の入力を参照します。このフィルタは1つの入力しか取ることができませんが、 Python Calculator (5.9.3 章 で説明されています)が使用するのと同じコードに基づいています。このコードは、このフィルタの複数の入力をPythonリストに入れます。したがって、 Python Annotation フィルタへの入力は inputs[0] として参照されます。
このフィルタは、現在の配列の関連付けの変数を式で使用できるようにするだけでなく、注釈値を計算するときに便利なその他の変数を提供します。
points: 点の位置(明示的な点を持つデータセットで使用可能)。time_value,t_value: ParaView に設定された現在の時刻の値。time_steps,t_steps: 入力で使用可能なタイムステップ数。time_range,t_range: 入力のタイムステップの範囲。time_index,t_index: ParaView の現在のタイムステップのインデックス。
上記の変数が定義されていない場合があります。イメージデータなど、入力に明示的に定義された点がない場合、points 変数は定義されません。入力がタイムステップを定義しない場合、time_* 変数と t_* 変数は定義されません。
- 最後に、
Python Calculatorのすべての機能が利用可能であり(5.9.3 章 を参照) 、 NumPyの統合、NumPyメソッドとSciPyメソッドへのアクセスなどを含みます。
Common Errors
時間関連の変数は、点データ配列またはセルデータ配列にインデックスを付けるために必要ではありません。フィルタで使用できるのは、現在のタイムステップ用にロードされた点配列とセル配列のみです。このフィルタ内から、任意のタイムステップの点またはセルデータにアクセスすることはできません。
このフィルタの機能を使用すると、次に示すように、その他のアノテーションソースとフィルタを再現できます。
Textsource: テキストMy annotationを生成するには、"My annotation"と書きます。Annotate Timesource:Time: {time:f}と同じ内容を表示するには、"Time: %f" % time_valueと記述してください。Annotate Attribute Datafilter:Select Input ArrayをEQPSに、Element Idを0に、Process Idを0に、PrefixをValue is:にそれぞれ設定するのと同じ結果を得るには、'Value is: %.12f' % (inputs[0].CellData['EQPS'][0])と書きます。Annotate Global Datafilter:Select Input ArrayをKEに、PrefixをValue is:に、Formatを%7.5gに、そして空のsuffixを設定するのと同じ注釈を生成するには"Value is: %7.5g" % (inputs[0].FieldData['KE'].Arrays[0][time_index])と書きます。Annotate Time Filter:FormatをTime: %fに、Shiftを3に、Scaleを2に設定するのと同じ結果を得るには、"Time: %f" % (2*time_value + 3)と書きます。
上記の例は、 Python Annotation フィルタの汎用性を示すためのものです。特殊な注釈ソースとフィルタを使用する方が、例のように式を入力するよりも便利です。