5. データのフィルタリング
可視化は、実験やシミュレーションによって得られた生データを、解釈や分析が可能な形になるまで変換するプロセスとして特徴づけらます。1.2 章 で導入された可視化パイプラインは、この概念を、パイプラインがソース、フィルタ、およびシンク(総称してパイプラインモジュールまたはアルゴリズムと呼ばれる)でセットアップされるデータフローパラダイムとして形式化しています。データフロー(data flows )はこのパイプラインを通り、シンクが消費できる形になるまで各ノードで変換されます。これまでの章では、ParaView にデータを取り込む方法(2 章 )と、データをビューに表示する方法(4 章)について説明しました。ParaView に取り込まれたデータに関連する属性データがすべて含まれており、既存のビューで直接表現できる形式になっている場合は、それだけで十分です。 しかし、可視化プロセスの真の力は、スライシング、コンタリング、クリッピングなど、フィルタとして利用可能な様々な可視化技術を利用することから得られます。この章では、このようなフィルタを使用してデータを変換するパイプラインの構築について説明します。
5.1. フィルタを理解する
ParaView では、フィルタは入力と出力を持つパイプラインモジュールまたはアルゴリズムです。入力データを取り込み、変換されたデータまたは出力結果を生成します。フィルタには、複数の入力ポートと出力ポートを含めることができます。 フィルタの入出力ポート数は固定です。各入力ポートは、フィルタ内の特定の目的または役割の入力データを受け入れます。(例: Resample With Dataset フィルタには2つの入力ポートがあります。Input と呼ばれるポートは、補間する属性を提供するデータセットを取り込むための入力ポートです。もう1つは Source と呼ばれ、再サンプリングするメッシュとして使用されるデータセットが受け入れられる入力ポートです。)
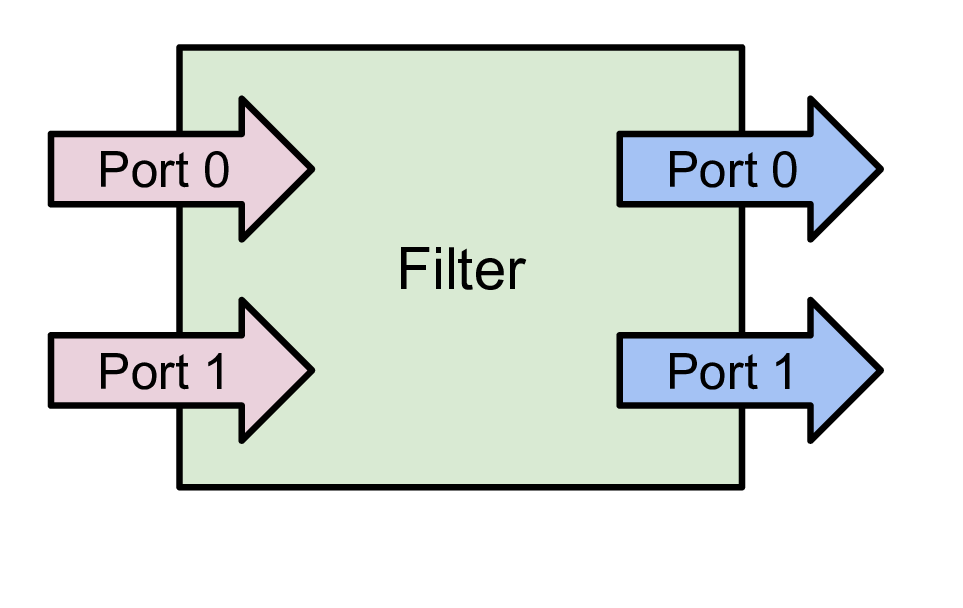
図 5.1 フィルタは、入力と出力を持つパイプラインモジュールです。データは入力を介してフィルタに入ります。フィルタはデータを変換し、その出力に結果データを作成します。フィルタは、1つまたは複数の入力ポートおよび出力ポートを持つことができます。各入力ポートは、オプションで複数の入力接続を受け入れることができます。
入力ポート自体は、複数の入力接続をオプションで受け入れることができます。たとえば、 Append Datasets フィルタは、複数のデータセットを追加して単一のデータセットを作成しますが、入力ポートは1つしかありません( Input と名付けられます)。ただし、そのポートは、追加される各データセットに対して複数の接続を受け付けることができます。フィルタは、特定の入力ポートが1つまたは複数の入力接続を受け入れることができるかどうかを定義します。
リーダーと同様に、フィルタのプロパティを使用してフィルタアルゴリズムを制御できます。使用できるプロパティは、フィルタ自体によって異なります。
5.2. paraview でのフィルタ作成
paraview で使用できるすべてのフィルタは、Filters メニューの下に一覧表示されます。これらは、さまざまなカテゴリに編成されています。ソースまたはリーダーによって生成されたデータを変換するフィルタを作成するには、Pipeline Browser でソースを選択してアクティブにし、Filters メニューの対応するメニュー項目をクリックします。メニュー項目が無効になっている場合は、アクティブソースがこのフィルタで変換できるデータを生成していないことを意味します。
Did you know?
Filters メニューのメニュー項目が無効になっている場合は、アクティブソースが予期されるタイプまたはフィルタに必要な特性のデータを生成していないことを示しています。WindowsおよびLinuxマシンでは、無効になっているメニュー項目にカーソルを置くと、ステータスバーにフィルタが使用できない理由が表示されます。
5.2.1. 複数の入力接続
フィルタを作成すると、アクティブソースはフィルタの最初の入力ポートに接続されます。 Append Datasets のようなフィルタは、その入力ポートに対して複数の入力接続を取ることができます。このような場合、複数のパイプラインモジュールをフィルタの1つの入力ポート上の接続として渡すには、 Pipeline Browser で関連するすべてのパイプラインモジュールを選択します。キー修飾子 CTRL (または ⌘ )および ⇧ を使用して、複数の項目を選択できます。複数のパイプラインモジュールを選択すると、入力ポートで複数の接続を受け入れるフィルタのみが Filters メニューで有効になります。
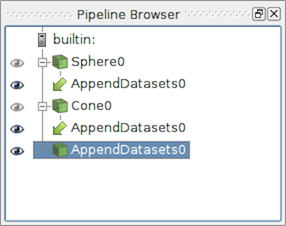
図 5.2 複数の入力接続を持つパイプラインを示す Pipeline Browser 。 Append Datasets フィルタは、その唯一の入力ポート Sphere0 と Cone0 に二つの入力接続を持ちます。
5.2.2. 複数の入力ポート
ほとんどのフィルタには入力ポートが1つしかありません。したがって、Filters メニューでフィルタ名をクリックすると、すぐに新しいフィルタインスタンスが作成され、 Pipeline Browser に表示されます。 Resample With Dataset などの特定のフィルタには複数の入力があり、フィルタを作成する前に設定する必要があります。このような場合、フィルタ名をクリックすると、図 5.3 に示すように、 Change Input Dialog がポップアップ表示されます。 このダイアログでは、各入力ポートに接続するパイプラインモジュールを選択できます。デフォルトでは、アクティブソースは最初の入力ポートに接続されます。ユーザーはそれらも自由に変更できます。
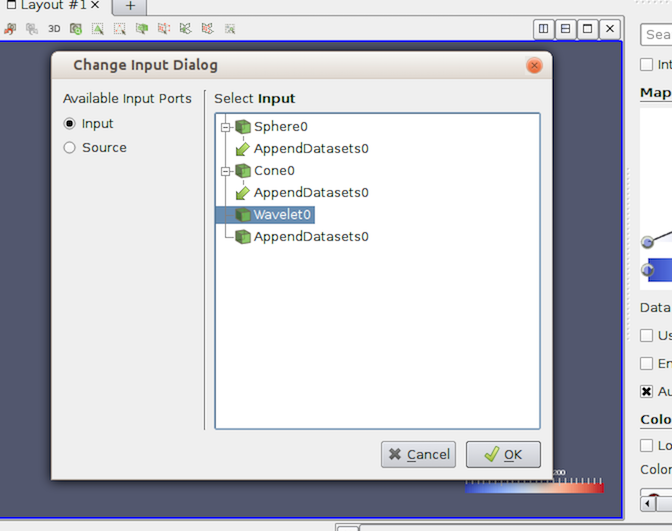
図 5.3 Change Input Dialog ダイアログは、複数の入力ポートを持つフィルタの各入力ポートの入力を選択できるようにします。このダイアログを使用するには、まず左側で編集する Input Port を選択し、この入力ポートに接続するパイプラインモジュールを選択します。他の入力ポートについても同じ手順を繰り返します。入力ポートが複数の入力接続を受け付けることができる場合、Pipeline Browser と同様に複数のモジュールを選択することができます。
5.2.3. 入力接続を変更する
paraview を使用すると、フィルタの作成後に入力をフィルタに変更できます。フィルタへの入力を変更するには、 Pipeline Browser でフィルタを右クリックしてコンテキストメニューを表示し、 Change Input... を選択します。これにより、複数の入力ポートを持つフィルタを作成した場合と同じ Change Input Dialog がポップアップ表示されます。このダイアログボックスを使用して、このフィルタの新しい入力を設定できます。
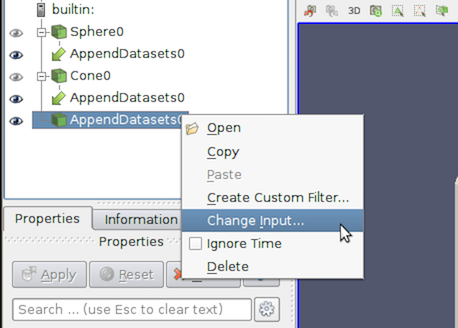
図 5.4 フィルタの入力を変更するオプションを示す Pipeline Browser のコンテキストメニュー
Did you know?
Filters メニューは新しいフィルタを作成するのに便利な方法ですが、 ParaView で利用可能なフィルタの長いリストでは、このメニューから特定のフィルタを手動で見つけることは非常に困難な場合があります。これを簡単にするために、ParaView にはクイック起動のメカニズムが組み込まれています。新しいフィルタ(またはソース)を作成したいときは、単に CTRL + Space または Alt + Space をタイプしてください。これでクイック起動のダイアログがポップアップします。ここで、希望するフィルタの名前を入力し始めます。入力すると、ダイアログが更新され、入力されたテキストに一致するフィルタとソースが表示されます。矢印キーで移動し、Enter キーで選択したフィルタ(またはソース)を作成することができます。Enter キーを押しながら ⇧ キーを押すと、フィルタを作成した後に Apply ボタンをクリックするのと同じように、作成したフィルタを素早く適用することができます。Filters メニューにあったように、フィルタは無効にすることができますが、デフォルトでは選択した項目が最初に有効になるフィルタであることに注意してください。これまでに入力したテキストをクリアするには、 Esc を使用することができます。2回目に Esc を押すと、新しいフィルタを作成せずにダイアログを閉じます。
5.3. pvpython でのフィルタ作成
pvpython でフィルタを作成するには、コンストラクタ関数として名前を使用してオブジェクトを作成します。
>>> from paraview.simple import *
...
>>> filter = Shrink()
paraview と同様に、フィルタは入力としてアクティブソースを使用します。また、関数の引数に入力を明示的に指定することもできます。
>>> reader = OpenDataFile(...)
...
>>> shrink = Shift(Input=reader)
5.3.1. 複数の入力接続
複数の入力接続を設定するには、次のように接続を指定します。:
>>> sphere = Sphere()
>>> cone = Cone()
# Simply pass the sources as a list to the constructor function.
>>> appendDatasets = AppendDatasets(Input=[sphere, cone])
>>> print(appendDatasets.Input)
[<paraview.servermanager.Sphere object at 0x6d75f90>, <paraview.servermanager.Cone object at 0x6d75c50>]
5.3.2. 複数の入力ポート
複数の入力ポートへの接続の設定は、入力ポートに適切な名前を付ける必要がある点を除き、複数の入力接続に似ています。
>>> sphere = Sphere()
>>> wavelet = Wavelet()
>>> resampleWithDataSet = ResampleWithDataset(Input=sphere, Source=wavelet)
5.3.3. 入力接続を変更する
Pythonで入力を変更するのは、フィルタの他のプロパティを設定するのと同じくらい簡単です。
# For filter with single input connection
>>> shrink.Input = cone
# for filters with multiple input connects
>>> appendDatasets.Input = [reader, cone]
# to add a new input.
>>> appendDatasets.Input.append(sphere)
# to change multiple ports
>>> resampleWithDataSet.Input = wavelet2
>>> resampleWithDataSet.Source = cone
5.4. paraview でのフィルタプロパティ変更
フィルタには、フィルタで使用される処理アルゴリズムを制御するために変更できるプロパティがあります。フィルタのプロパティの変更と表示は、リーダーやソースなどの他のパイプラインモジュールと同じです。 これらのプロパティが使用可能な場合は、 Properties パネルを使用して表示および変更できます。 Properties パネルの効果的な使用方法については、1 章 を参照してください。このパネルにはアクティブソース( Active Source )に存在するプロパティだけが表示されるので、対象のフィルタがアクティブであることを確認する必要があります。フィルタをアクティブにするには、 Pipeline Browser を使用してフィルタをクリックし、選択します。
5.5. pvpython でのフィルタプロパティ変更
pvpython を使用すると、使用可能なプロパティにフィルタオブジェクトのプロパティとしてアクセスでき、その値を名前で取得または設定できます(入力接続の変更(5.3.3 章 )に似ています)。
# You can save the object reference when it's created.
>>> shrink = Shrink()
# Or you can get access to the active source.
>>> Shrink() # <-- this will make the Shrink the active source.
>>> shrink = GetActiveSource()
# To figure out available properties, you can always use help.
>>> help(shrink)
Help on Shrink in module paraview.servermanager object:
class Shrink(SourceProxy)
| The Shrink filter
| causes the individual cells of a dataset to break apart
| from each other by moving each cell\'s points toward the
| centroid of the cell. (The centroid of a cell is the
| average position of its points.) This filter operates on
| any type of dataset and produces unstructured grid
| output.
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| Input
| This property specifies the input to the Shrink
| filter.
|
| ShrinkFactor
| The value of this property determines how far the points
| will move. A value of 0 positions the points at the centroid of the
| cell; a value of 1 leaves them at their original
| positions.
....
# To get the current value of a property:
>>> sf = shrink.ShrinkFactor
>>> print sf
0.5
# To set the value
>>> shrink.ShrinkFactor = 0.75
この章の残りの部分では、一般的に使用されるフィルタについて詳しく説明します。実行する操作の種類に基づいて、カテゴリの下にグループ化されます。
5.6. サブセットデータのフィルタ
これらのフィルタは、入力データセットからサブセットを抽出するために使用されます。このサブセットの定義方法と抽出方法は、フィルタのタイプによって異なります。
5.6.1. Clip
Clip は、(平面、球、ボックスなど)陰関数を使用するか、入力データセット内のスカラーデータ配列の値を使用して、任意のデータセットをクリップするために使用されます。スカラー配列は、単一のコンポーネントを持つ点またはセルの属性配列です。クリッピングでは、入力データセット内のすべてのセルを繰り返し処理してから、陰関数によって定義された空間の 外側 と見なされるセル、または選択された値よりも小さい属性値を持つセルを削除します。クリッピングサーフェスをまたぐセルの場合、これらは指定された陰関数(またはスカラー値より大きい)の内部にあるセルの部分を通過するために クリップされます 。
このフィルタは、複合データセットの場合、任意のデータセットを非構造格子(3.1.7 章)または非構造格子のマルチブロック (3.1.10 章)に変換します。
5.6.1.1. paraview でのClip
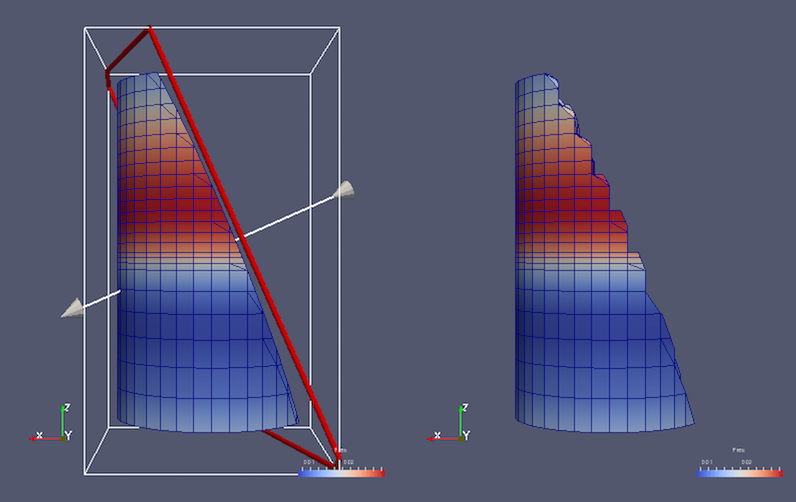
図 5.5 インプリシット平面でクリップする場合の、 Crinkle Clip をオフにした Clip フィルタ(左)とオンにした Clip フィルタ(右)による結果の比較。左側の図は、クリッピング操作のインプリシット平面をインタラクティブに配置するために使用される3Dウィジェットも示しています。
Clip フィルタを作成するには、 Filters>Common または Filters>Alphabetical メニューを使用することができます。このフィルタは Common フィルタツールバーからもアクセスすることができます。pqClip|ボタンをクリックすると、このフィルタを作成することができます。

図 5.6 よく使用されるフィルタにすばやくアクセスするための paraview の Common フィルタ
Properties パネルに、このフィルタで使用可能なプロパティが表示されます。最初に選択する必要があるものの1つは、 Clip Type です。 Clip Type は、クリッピング操作に使用する暗黙的な関数のタイプを指定するために使用されます。使用可能なオプションは、 Plane 、 Box 、 Sphere 、 Scalar です。これらのオプションのいずれかを選択すると、パネルが更新され、暗黙的な関数の定義に使用されるプロパティが表示されます。たとえば、 Plane の Origin と Normal 、 Center 、 Sphere の Radius などです。 Scalar を選択すると、パネルでクリップするデータ配列と値を選択できます。データ値が選択した値以上のセルは in と見なされ、フィルタを通過します。
Did you know?
陰関数を使用してクリップすると、ParaView によってアクティブビューにウィジェットがレンダリングされます。このウィジェットを使用して、 3D widgets という陰関数を対話的に制御できます。3Dウィジェットを操作すると、パネルが更新されて現在の値が反映されます。3Dウィジェットは、実際の可視化シーンの一部としてではなく、補助として考慮されます。したがって、アクティブソースを変更し、 Properties パネルがこのフィルタから離れると、3Dウィジェットは自動的に非表示になります。
Inside Out オプションを使用すると、このフィルタの動作を逆にすることができます。基本的には、指定されたクリッピングスペースの内側と外側で考慮されるものの概念を反転させます。
このフィルタで実際に境界上のセルをクリップしたくないが、入力セルの構造を保持し、セル全体を境界を通過させたい場合は、 Crinkle Clip をチェックします(図 5.5)。Scalar でクリッピングする場合、このオプションは使用できません。
5.6.1.2. pvpython でのClip
次のスクリプトは、pvpython で Clip フィルタを使用する方法を示しています。
# Create the Clip filter.
>>> clip = Clip(Input=...)
# Specify a 'ClipType' to use.
>>> clip.ClipType = 'Plane'
# You can also use the SetProperties API instead.
>>> SetProperties(clip, ClipType='Plane')
>>> print(clip.GetProperty('ClipType').GetAvailable())
['Plane', 'Box', 'Sphere', 'Scalar']
# To set the plane origin and normal
>>> clip.ClipType.Origin = [0, 0, 0]
>>> clip.ClipType.Normal = [1, 0, 0]
# If you want to change to Sphere and set center and
# radius, you can do the following.
>>> clip.ClipType = 'Sphere'
>>> clip.ClipType.Center = [0, 0, 0]
>>> clip.ClipType.Radius = 12
# Using SetProperties API, the same looks like
>>> SetProperties(clip, ClipType='Sphere')
>>> SetProperties(clip.ClipType, Center=[0, 0, 0],
Radius = 12)
# To set Crinkle clipping.
>>> clip.Crinkleclip = 1
# For clipping with scalar, you pick the scalar array
# and then the value as follows:
>>> clip.ClipType = 'Scalar'
>>> clip.Scalars = ('POINTS', 'Temp')
>>> clip.Value = 100
# As always, to get the list of available properties on
# the clip filter, use help()
>>> help(clip)
Help on Clip in module paraview.servermanager object:
class Clip(SourceProxy)
| The Clip filter
| cuts away a portion of the input dataset using an
| implicit plane. This filter operates on all types of data
| sets, and it returns unstructured grid data on
| output.
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| ClipType
| This property specifies the parameters of the clip
| function (an implicit plane) used to clip the dataset.
|
| Crinkleclip
| This parameter controls whether to extract entire cells
| in the given region or clip those cells so all of the output one stay
| only inside that region.
|
| Input
| This property specifies the dataset on which the Clip
| filter will operate.
|
| InsideOut
| If this property is set to 0, the clip filter will
| return that portion of the dataset that lies within the clip function.
| If set to 1, the portions of the dataset that lie outside the clip
| function will be returned instead.
...
# To get help on a specific implicit function type, make it the active
# ClipType and then use help()
>>> clip.ClipType = 'Plane'
>>> help(clip.ClipType)
Help on Plane in module paraview.servermanager object:
class Plane(Proxy)
...
Common Errors
イメージデータのような構造データセットをクリッピングすることは、このフィルタがクリッピング操作自体の性質のために構造データセットを非構造格子に変換するので、メモリ必要量を劇的に増加させることがあることを忘れがちです。構造データセットの場合は、必要に応じて、代わりに Slice フィルタまたは Extract Subset フィルタを使用することを検討してください。これらは完全に同一の操作ではありませんが、多くの場合は十分です。
5.6.2. Slice
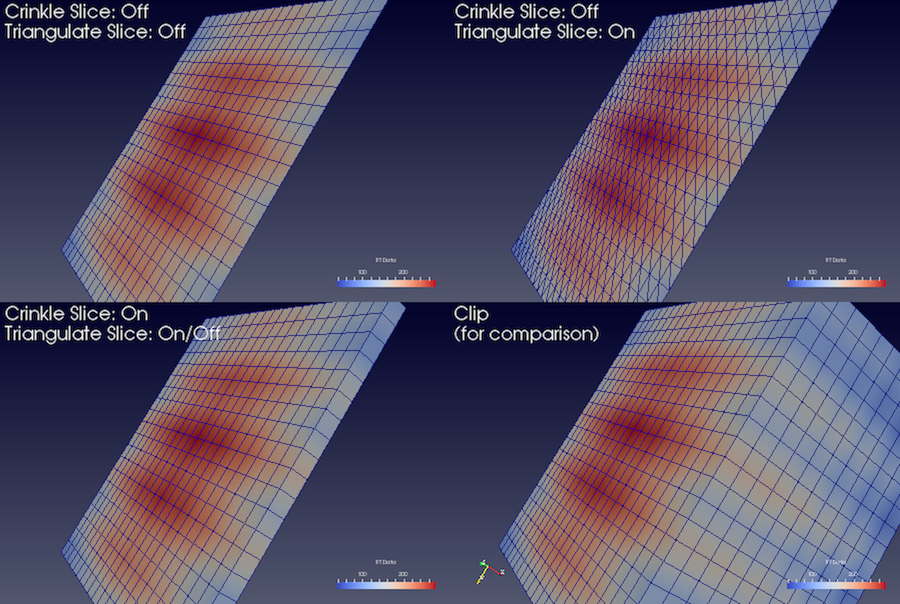
図 5.7 オプションの異なる陰関数平面を使用してイメージデータをスライスする場合の Slice フィルタによる結果の比較。左下のイメージは、同じ陰関数を使用してクリップした場合に Clip フィルタによって生成される出力を示しています。
Slice フィルタは、平面、球、ボックスなどの陰関数を使用して入力データセットをスライスします。このフィルタは、陰関数境界に沿ってデータ要素を返すため、これは次元削減フィルタ(クリンクルスライシングが有効な場合を除く)です。つまり、入力データセットに4面体や6面体などの3D要素が含まれている場合、出力には2D要素、3角形、四角形が含まれます。2D要素を含むデータセットをスライスすると、結果は線分になります。
このフィルタで使用できるプロパティとフィルタの設定方法は、 Clip フィルタとよく似ていますが、いくつかの点が異なります。同様の方法として、陰関数の設定があります。 Plane 、 Box 、 Sphere 、 Cylinder のような選択肢があり、 Crinkle slice を切り替えるオプション(すなわち、セルの切断を回避するために、陰関数と交差する入力データセットから完全なセルを渡す)もあります。
異なる点は、 Scalar (これには Contour フィルタを使用可能)によるスライスがないことと、新しいオプション Triangulate the slice が追加されていることです。図 5.7 は、さまざまなスライスプロパティが変更された場合に生成されるメッシュの違いを示しています。
Slice フィルタは、 Slice レプリゼンテーションよりも汎用性があります。第1に、 Slice レプリゼンテーションはイメージデータセットでのみ使用できますが、 Slice フィルタは任意のタイプの3Dデータセットで使用できます。第二に、表現は画像ボクセル位置でXY, YZまたはXZ平面に配向された2Dスライスから成る画像のサブセットを抽出し、一方、フィルタによって使用される平面は任意に配置できます。第3に、 Slice レプリゼンテーションは常にフラットなオブジェクトを示し、照明がスライス上のデータ値の解釈に干渉する可能性があるため、照明は Slice レプリゼンテーションに適用されません。ただし、照明は Slice フィルタの結果に適用されます。最後に、 Slice レプリゼンテーションは、データセット内のセルと平面の交差を計算する必要がないため、異なるスライスを更新してスクラブするフィルタよりも高速です。
paraview では、このフィルタは Filters メニューの他に、Common filters toolbar の  ボタンを使って作成することができます。
ボタンを使って作成することができます。
5.6.3. Extract Subset
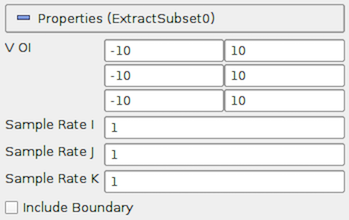
図 5.8 使用可能なすべてのプロパティ(詳細プロパティを含む)を表示する、 Extract Subset に対する Properties パネル
イメージデータセット(3.1.3 章)、直線格子 (3.1.4 章) 、曲線格子 (3.1.5 章)などの構造データセットの場合、 Extract Subset フィルタを使用して注目の領域またはサブグリッドを抽出できます。抽出する領域は、構造化座標 (\(i\), \(j\), \(k\) の値) を使用して指定します。構造データセットでは、入力データ型が保持されるため、可能な限りこのフィルタを Clip または Slice より優先して使用してください。サブセットの抽出に加えて、このフィルタを使用して、各構造化次元に沿ってサンプルレートを指定することにより、データセットをより粗い解像度に再サンプリングすることもできます。
5.6.3.1. paraview でのExtract Subset
これは、Common filters toolbar  で利用できるフィルタの1つです。関心のある領域を指定するには、
で利用できるフィルタの1つです。関心のある領域を指定するには、 VOI プロパティを使用します。各行の構造化次元( \(i\), \(j\), \(k\), )ごとに、min と max の値が指定されます。 Sample Rate I 、Sample Rate J、Sample Rate K は、サブサンプリングレートを指定します。サブサンプリングするには、1より大きい値を設定します。Include Boundary は、境界スラブを抽出結果に含めるかどうかを決定するために使用します。この場合、その次元に沿ったサブサンプリング率が 1 よりも大きく、境界スラブがスキップされることになります。
5.6.4. Threshold

図 5.9 ParaView データの iron_protein.vtk データセットに対して Threshold フィルタを使用した結果
Threshold フィルタは、選択されたしきい値の方法に応じて,指定された範囲内にあるスカラー値を持つ入力データセットのセルを抽出します。このフィルタは、点を中心としたデータでも、セルを中心としたデータでも動作します。どのような種類のデータセットでも入力として使用できます。このフィルタは非構造格子を出力します。
ポイントデータによるしきい値設定では、 All Scalars がチェックされている場合、範囲内のスカラー値を持つ すべての 点を持つセルが渡されます。それ以外の場合は、しきい値基準を満たす 任意の 点を持つセルが渡されます。
5.6.4.1. paraview でのThreshold

図 5.10 Threshold フィルタに対する Properties パネル
このフィルタは Common フィルタツールバー上では  として表示されます。コンボボックスから閾値を設定する
として表示されます。コンボボックスから閾値を設定する Scalars を選択した後、 Lower Threshold と Upper Threshold の値を変更して、範囲を指定することができます。スライダーで表示される範囲では不十分な場合、入力ボックスに手動で値を入力することも可能です。この場合、値は意図的に現在のデータ範囲に固定されることはありません。
また、 Threshold Method コンボボックスを使って、しきい値の方法を選択することもできます。
Between: スカラー値がLower ThresholdとUpper Thresholdの間にあるセルを抽出します。Below Lower Threshold:Lower Thresholdよりも小さいスカラー値を持つセルを抽出します。Above Upper Threshold:Upper Thresholdよりも大きいスカラー値を持つセルを抽出します。
5.6.4.2. pvpython でのThreshold
# Create the filter. If Input is not specified, the active source will be
# used as the input.
>>> threshold = Threshold(Input=...)
# Here's how to select a scalar array.
>>> threshold.Scalars = ("POINTS", "scalars")
# The value is a tuple where the first value is the association: either "POINTS"
# or "CELLS", and the second value is the name of the selected array.
>>> print(threshold.Scalars)
['POINTS', 'scalars']
>>> print(threshold.Scalars.GetArrayName())
'scalars'
>>> print(threshold.Scalars.GetAssociation())
'POINTS'
# Different threshold methods are available and are set using one of the following:
>>> threshold.ThresholdMethod = "Between" # Uses both lower and upper values
>>> threshold.ThresholdMethod = "Below Lower Threshold" # Uses only lower value
>>> threshold.ThresholdMethod = "Above Upper Threshold" # Uses only upper value
# The adequate threshold values are then specified as:
>>> threshold.LowerThreshold = 63.75
>>> threshold.UpperThreshold = 252.45
入力データセットで使用可能な配列のタイプとその範囲を決定するには、3.3 章 のデータ情報に関する説明を参照してください。
5.6.5. Iso Volume
Iso Volume フィルタは、指定された範囲を満たすセルがスカラー値である入力から出力データセットを作成するために使用するという点で、 Threshold と似ています。実際、セルデータスカラーが選択されている場合、フィルタは Threshold と同じです。ただし、ポイントデータスカラーの場合、このフィルタはスカラーでクリッピングする際に Clip フィルタと同様に機能し、スカラー範囲によって形成されるアイソサーフェスに沿ってセルがクリッピングされます。
5.6.6. Extract Selection
Extract Selection は、データセットから選択した要素を抽出するための汎用フィルタです。ParaView では、いくつかの方法で選択できます。選択を行うと、このフィルタを使用して、選択した要素を新しいデータセットとして抽出し、さらに処理することができます。このフィルタについては、6.6 章 の ParaView で選択項目を確認する際に詳しく説明します。
5.7. 幾何的操作に関するフィルタ
これらのフィルタは、トポロジや接続性に影響を与えずにデータセットのジオメトリを変換するために使用されます。
5.7.1. Transform
Transform を使用すると、データセットを自由に移動、回転、およびスケーリングできます。変換は、データセットをスケーリングし、回転してから移動することによって適用されます。 指定された値に基づきます。
これはジオメトリ操作フィルタであるため、このフィルタは入力データセットの接続性には影響しません。入力データセットの型を保存しようとしますが、変換されたデータセットが入力と同じデータ型で表現できなくなる場合があります。例えば、回転によって変換されるイメージデータ (3.1.3 章)および直線格子(3.1.4 章)では、出力データセットは軸整列されない可能性があり、したがって、いずれのデータタイプとしても表すことができません。このような場合、データセットは構造格子、または曲線格子に変換されます(3.1.5 章)。曲線格子は他の2つほどコンパクトではないので、より一般的なデータ型で結果を保存する必要があるということは、メモリーフットプリントがかなり増加することを意味します。
5.7.2. paraview でのTransform
Filters > Alphabetical メニューから新しい Transform を作成できます。作成したトランスフォームを移動、回転、スケールとして設定し、 Properties パネルを使用して使用できます。 Clip と同様に、このフィルタでは3Dウィジェットを使用してインタラクティブに変換を設定することもできます。

図 5.11 インタラクティブに変換を設定するために使用できる3Dウィジェットを表示する Transform フィルタ
5.7.3. pvpython でのTransform
# To create the filter(if Input is not specified, the active source will be
# used as the input).
>>> transform = Transform(Input=...)
# Set the transformation properties.
>>> transform.Translate.Scale = [1, 2, 1]
>>> transform.Transform.Translate = [100, 0, 0]
>>> transform.Transform.Rotate = [0, 0, 0]
5.7.4. Reflect

図 5.12 Reflect フィルタを使用すると、特定の軸平面に沿ってデータセットを反射させることができます。
Reflect を使用すると、任意のデータセットを軸平面に沿って反射させることができます。データセットの境界ボックスによって形成される平面の1つとなる軸平面を選択できます。そのためには、 Plane を X Min 、X Max 、Y Min 、Y Max 、Z Min 、Z Max のように設定します。任意の軸平面を基準に反射させるには、 Plane プロパティで X 、 Y 、または Z を選択し、 Center を原点からオフセットした平面に設定します。
このフィルタは、入力データセットを反映し、非構造格子を生成します(3.1.7 章)。したがって、構造データセットを扱う場合は、 Clip フィルタと Threshold フィルタに同じ注意事項が適用されます。
5.7.5. Warp By Vector
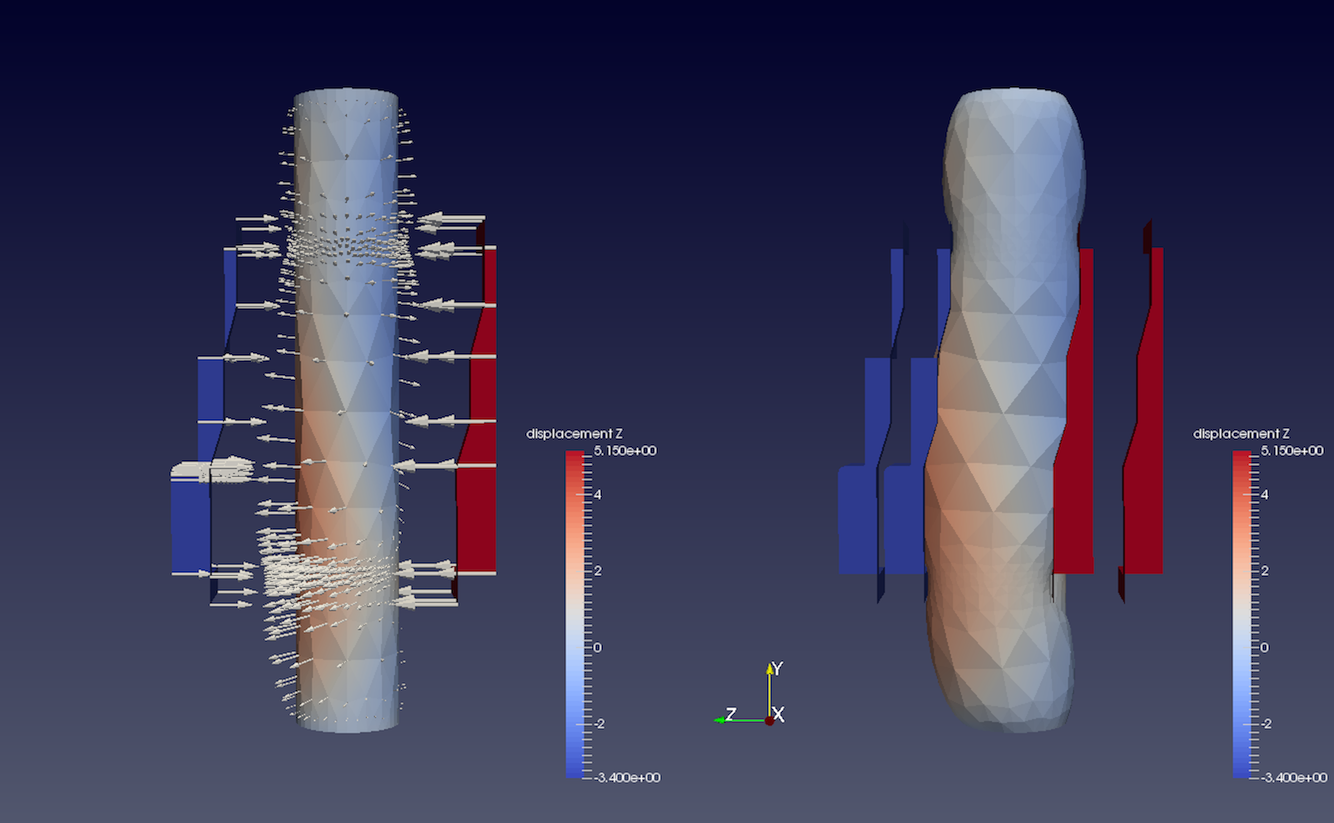
図 5.13 Warp By Vector フィルタを使用すると、左側に表示されている元のデータ内の点を、を 変位 ベクトル(矢印記号。5.8.1 章 で示されます)を使用して、右側に表示されている結果に置き換えることができます。
Warp By Vector を使用すると、データセット自体のベクトルを使用して、入力メッシュ内の点座標を変位させることができます。使用するベクトルを選択するには、 Properties パネルの Vectors プロパティを使用します。 Scale Factor は、適用される変位のスケーリングに使用できます。
5.7.6. Warp By Scalar
Warp By Scalar は、入力メッシュを変位させるという点で Warp By Vector に似ています。ただし、入力データセットではスカラー配列を使用します。変位の方向は、 Normal プロパティを使用して明示的に指定するか、 Use Normal をチェックして点の位置で法線を使用することができます。
5.8. サンプリングに関するフィルタ
これらのフィルタは、入力として取得したデータセットから、いくつかの重要なフィーチャを表す新しいデータセットを計算します。
5.8.1. Glyph
Glyph は、入力データセット内のポイント位置にマーカーまたはグリフを配置するために使用します。グリフは、それらのポイントのベクトルとスカラの属性に基づいて、方向を指定したり、尺度を変更することができます。
このフィルタを paraview で作成するには、 Filters メニューと Common filters ツールバーの  ボタンを使用します。まず、グリフの種類を
ボタンを使用します。まず、グリフの種類を Glyph Type にあるオプションの中から選択します。選択肢には、 Arrow , Sphere , Cylinder などがあります。次に、Orientation Array として使用する点配列を選択します(No orientation array を選択すると、グリフの向きが変わりません)。同様に、グリフの Scale Array として使用する点配列を選択します(No scale array を選択した場合は、スケーリングは行われません)。
Scale Array がベクトル配列に設定されている場合、 Vector Scale Mode プロパティを使用して、各グリフの変換に使用するベクトルのプロパティを選択できます。 Scale by Magnitude を選択すると、点のグリフはその点のベクトルの大きさによってスケーリングされます。 Scale by Components を選択すると、グリフはその次元のベクトル成分によって各次元で別々にスケーリングされます。
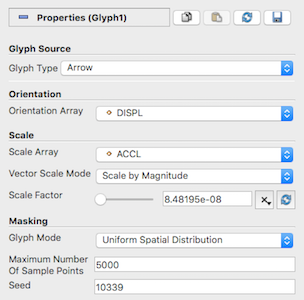
図 5.14 Glyph フィルタに対する Properties パネル
スケールファクターは Scale Array や Vector Scale Mode のプロパティとは関係なく、すべてのグリフに対して一定のスケーリングを適用するために使用されます。良いスケールファクターを選択するには、入力データセットの境界、選択した Scale Array と Vector Scale Mode 、そして Scale Array として選択した配列の範囲などのいくつかの事柄に依存します。 Scale Factor ウィジェットの横にある  ボタンを使用すると、現在のデータセットとスケーリングプロパティに基づいて、通常は妥当なスケールファクターの値を
ボタンを使用すると、現在のデータセットとスケーリングプロパティに基づいて、通常は妥当なスケールファクターの値を paraview に選択させることができます。
Masking プロパティは、入力データセットからグリフされる点を制御します。Glyph Mode は、点をグリフに選択する方法を制御します(図 5.15)。使用可能なオプションは次のとおりです。
All Points:入力データセット内のすべての点をグリフ対象として選択します。このモードは、入力データセットの点が比較的少ない場合にのみ、注意して使用してください。入力データセット内のすべての点がグリフ化されるため、視覚的な混乱が生じるだけでなく、メモリが消費され、グリフの生成とレンダリングに時間がかかる可能性があります。Every Nth Points:入力データセット内のすべての \(n^{th}\) 点をグリフィング対象として選択します。\(n\) は、Strideを使用して指定できます。Strideを1に設定すると、All Pointsと同じ結果になります。Uniform Spatial Distribution:ランダムな点のセットを選択します。このアルゴリズムは、最初に入力データセットの境界ボックスによって定義された空間においてMaximum Number of Sample Pointsまでを計算することによって動作します。次に、このサンプルポイントセット内の点に近い入力データセット内の点がグリフされます。Seedは、サンプルポイントの生成に使用される乱数ジェネレータのシードに使用されます。これにより、ランダムなサンプルポイントが再現可能で一貫性のあるものになります。
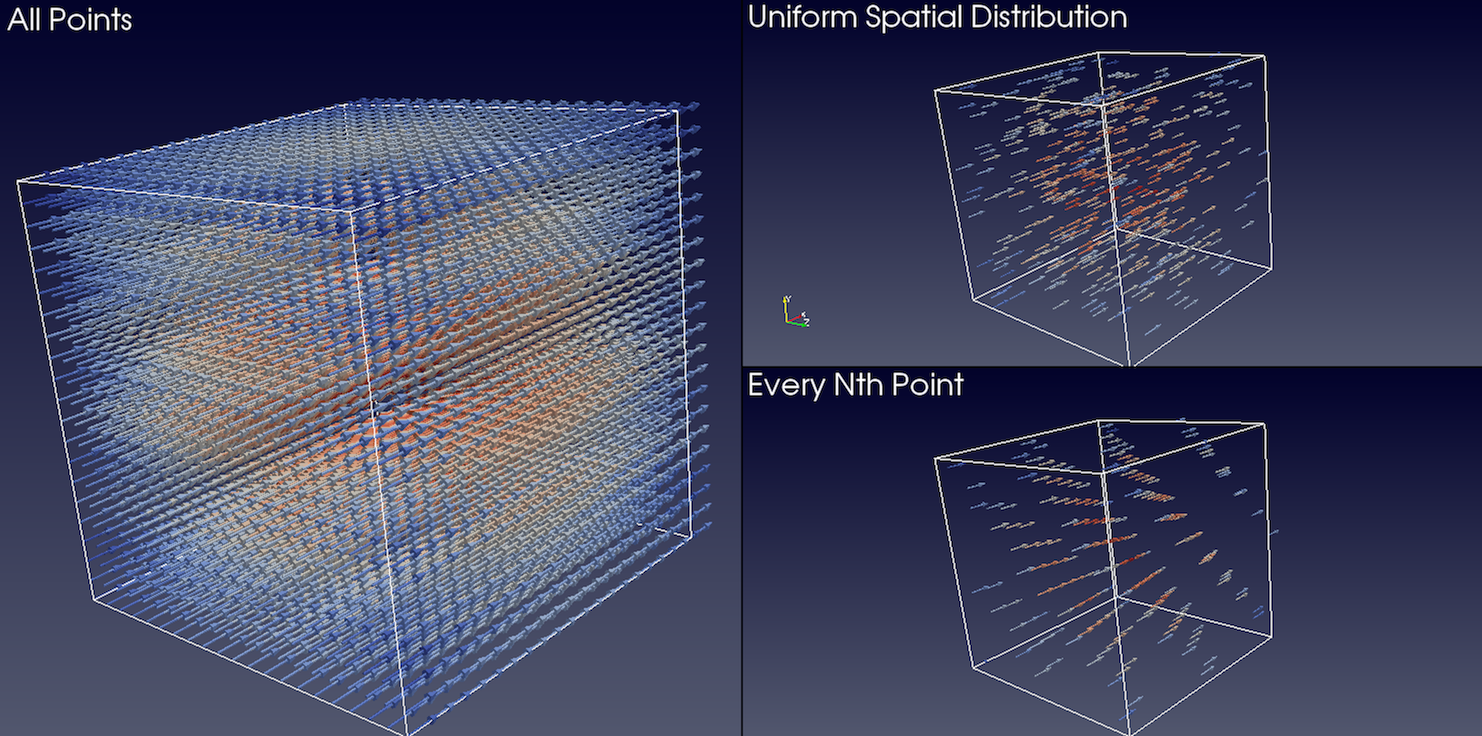
図 5.15 Wavelet ソースによって生成された同じデータセットに適用した場合の、さまざまな Glyph Mode の比較
Did you know?
Glyph 表現は、 Glyph フィルタが使用される多くの可視化で使用できます。同様の機能を持つ Glyph フィルタよりも高速にレンダリングでき、メモリ消費も少なくて済みます。3Dジオメトリの生成が必要な状況 (たとえば、グリフジオメトリをファイルに書き出す場合) では、 Glyph フィルタが必要です。
5.8.2. Glyph With Custom Source
Glyph With Custom Source は Glyph と同じですが、 Glyph Type という限定されたセットの代わりに、 Pipeline Browser で使用可能なポリゴンデータセット (3.1.8 章)を生成する任意のデータソースを選択できる点が異なります。このフィルタを使用するには、 Pipeline Browser} でグリフするデータソースを選択し、このフィルタをアタッチします。ダイアログが表示され、 Input (選択したソースがデフォルトになります)と Glyph Source を設定できます。
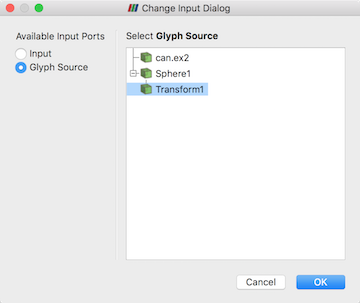
図 5.16 Glyph With Custom Source フィルタでの Input と Glyph Source の設定"
5.8.3. Stream Tracerフィルタ
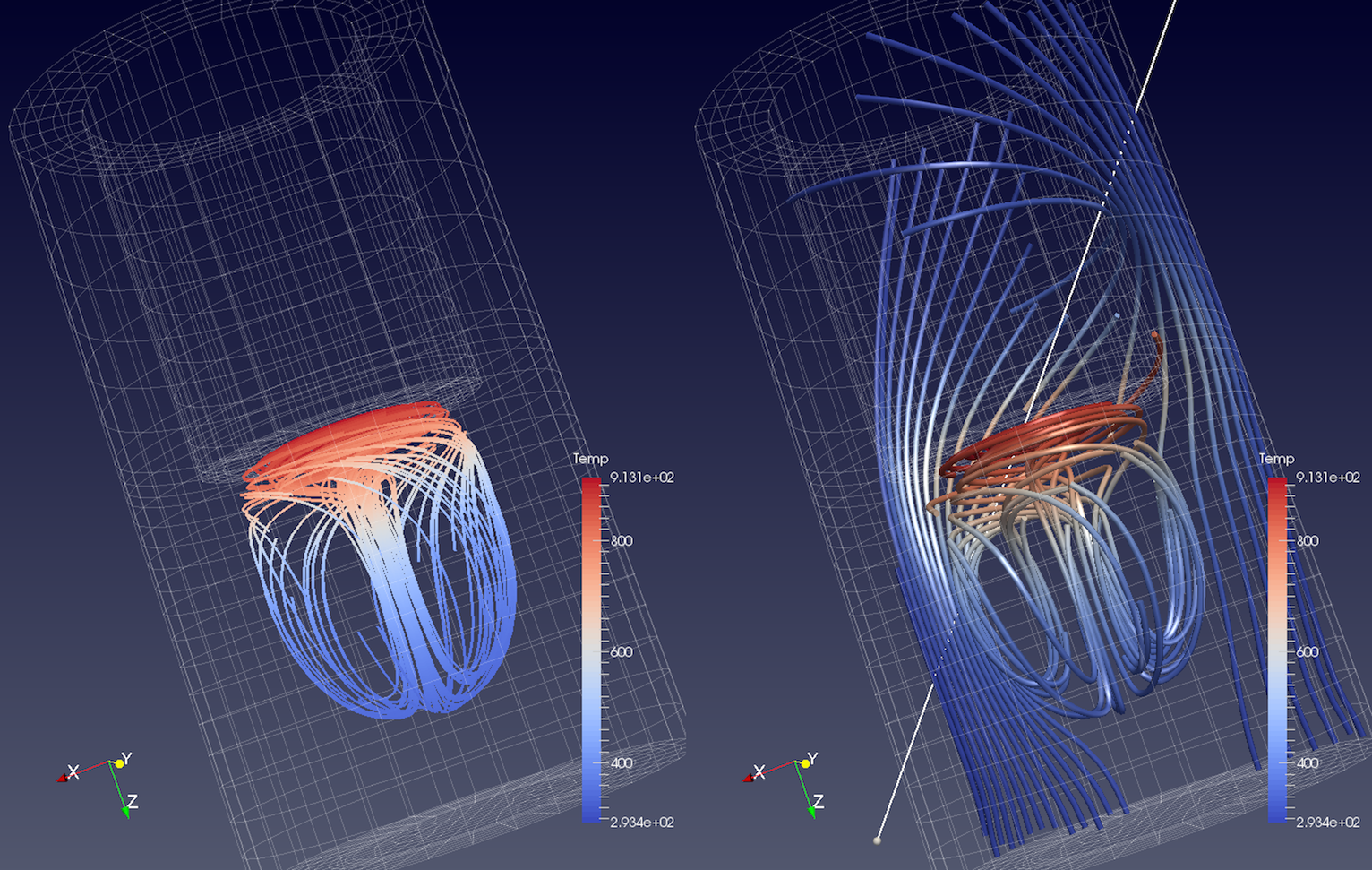
図 5.17 Point Source (左)と High Resolution Line Source (右)を使用して disk_out_ref.ex2 データセットから生成された流線。左側では、 Stream Tracer フィルタの出力に Tube フィルタを追加し、シェーディングが不足して可視化が困難な1Dの折れ線ではなく、3Dのチューブを生成しました。
Stream Tracer フィルタは、ベクトルフィールドの流線を生成するために使用されます。 可視化では、ストリームラインとは、データセット内のベクトルフィールドに瞬時に接している曲線を指します。これらは、データセット内の粒子がその時点で移動する方向を示す。このアルゴリズムは、データセット内の seed ポイントと呼ばれる一連の点を取得し、これらのシードポイントから始まるストリームラインを統合することによって機能します。
paraview では、 Filters メニューと Common filters toolbar の  ボタンを使って、このフィルタを作成することができます。このフィルタを使用するには、まず流線を生成するための
ボタンを使って、このフィルタを作成することができます。このフィルタを使用するには、まず流線を生成するための Vectors として使用する属性配列を選択します。 積分パラメータ Integration Parameters では、積分の方向 Integration Direction や、使用する積分アルゴリズムの種類 Integrator Type を指定し、流線の積分を調整することができます。高度な統合パラメータは Properties パネルの詳細表示で利用でき、ステップサイズなどを指定して統合をさらに調整することができます。最大流線長 Maximum Streamline Length は、流線の最大長を制限するために使用し、長ければ長いほど、生成される流線は長くなります。
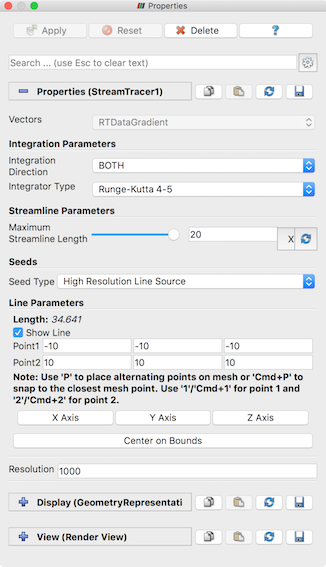
図 5.18 Stream Tracer フィルタのデフォルトのプロパティを示す Properties パネル
Seeds グループでは、流線を生成するためのシードポイントの生成方法を設定できます。次の2つのオプションがあります。 Point Source は、指定したパラメータに基づいて、ユーザが指定した Point の周囲に点の塊を生成します。 High Resolution Line Source は、ユーザが指定したラインに沿ってシードポイントを生成します。アクティブな Render View に表示されている3Dウィジェットを使用して、点群の中心をインタラクティブに配置したり、ラインを定義することができます。
Did you know?
Stream Tracer フィルタは、生成されたストリームラインごとに1Dラインを持つポリデータを生成します。1Dラインは、 Render View でサーフェスのようにシェーディングできないため、流線を追うのが困難な箇所を可視化できます。流線に3D構造を与えるには、流線の出力に Tube フィルタを適用します。 Tube フィルタのプロパティを使用すると、チューブの厚みを制御できます。チューブの厚みは、データ配列(流線のサンプルポイントにおけるベクトルフィールドの大きさなど)に基づいて変更することもできます。
paraview で Stream Tracer フィルタを使用するスクリプトは、通常次のようになります:
# find source
>>> disk_out_refex2 = FindSource('disk_out_ref.ex2')
# create a new 'Stream Tracer'
>>> streamTracer1 = StreamTracer(Input=disk_out_refex2,
SeedType='Point Source')
>>> streamTracer1.Vectors = ['POINTS', 'V']
# init the 'Point Source' selected for 'SeedType'
>>> streamTracer1.SeedType.Center = [0.0, 0.0, 0.07999992370605469]
>>> streamTracer1.SeedType.Radius = 2.015999984741211
# show data in view
>>> Show()
# create a new 'Tube'
>>> tube1 = Tube(Input=streamTracer1)
# Properties modified on tube1
>>> tube1.Radius = 0.1611409378051758
# show the data from tubes in view
>>> Show()
5.8.4. Stream Tracer With Custom Source
Stream Tracer を使用すると、シード点を点群または線分ソースとして指定できます。ただし、別のデータプロデューサから独自のシードポイントを提供する場合は、 Stream Tracer With Custom Source を使用します。 Glyph With Custom Source と同様に、このフィルタではシードポイントとして使用する2番目の入力コネクションを選択できます。

図 5.19 Slice フィルタの出力をシードポイントの Source として使用し、disk_out_ref.ex2 データセットから生成される流線。
5.8.5. Resample With Datasetフィルタ

図 5.20 Resample With Dataset の例。左側は、マルチブロック四面体メッシュ ( Input ) です。中央には、マルチブロックの非構造格子( Source ) が表示されます。 Input のアウトラインもこのビューに表示されます。フィルタを適用した結果を右側に示します。
Resample With Dataset は、あるデータセットの点属性とセル属性を別のデータセットの点にサンプリングします。2つのデータセットは、2つの入力ポート Input (再サンプルする属性を提供するデータセット)および Source (サンプリングする点を提供するデータセット)を使用してフィルタに提供されます。このフィルタは、Filters メニューで使用できます。
5.8.6. Resample To Imageフィルタ
Resample To Image は、 Resample With Dataset を特殊化したものです。 フィルタは1つの入力を取り、その点とセルの属性を点の一様な格子上にサンプリングします。一様な格子の境界と範囲は、プロパティパネルを使用して指定できます。デフォルトでは、境界は入力データセットの境界に設定されます。フィルタの出力はイメージデータセットです。
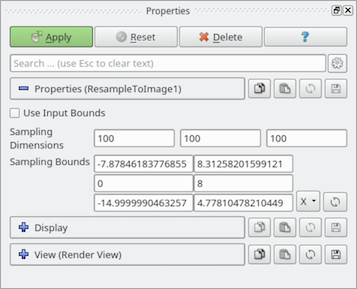
図 5.21 Resample To Image フィルタに対する Properties パネル

図 5.22 Resample To Image の例。左側に入力(非構造格子)、中央に出力(イメージデータ)が表示されます。右側は、再サンプリングされたデータのボリュームレンダリングです。
一部の操作は、一様な格子データセットでより効率的に実行できます。 ボリュームレンダリングはそのような操作の1つです。このような操作を実行する前に、Resample to Image フィルタを使用して任意のデータセットをイメージデータに変換できます。
5.8.7. Probe
Probe は、入力データセットを特定の点位置でサンプリングし、点を含むセルのセルデータ属性と補間されたポイントデータ属性を取得します。 SpreadSheet View または Information パネルを使用して、検出された値を検査できます。プローブの位置は、アクティブな Render View に示されている対話型の3Dウィジェットを使用して指定できます。
5.8.8. Plot over line
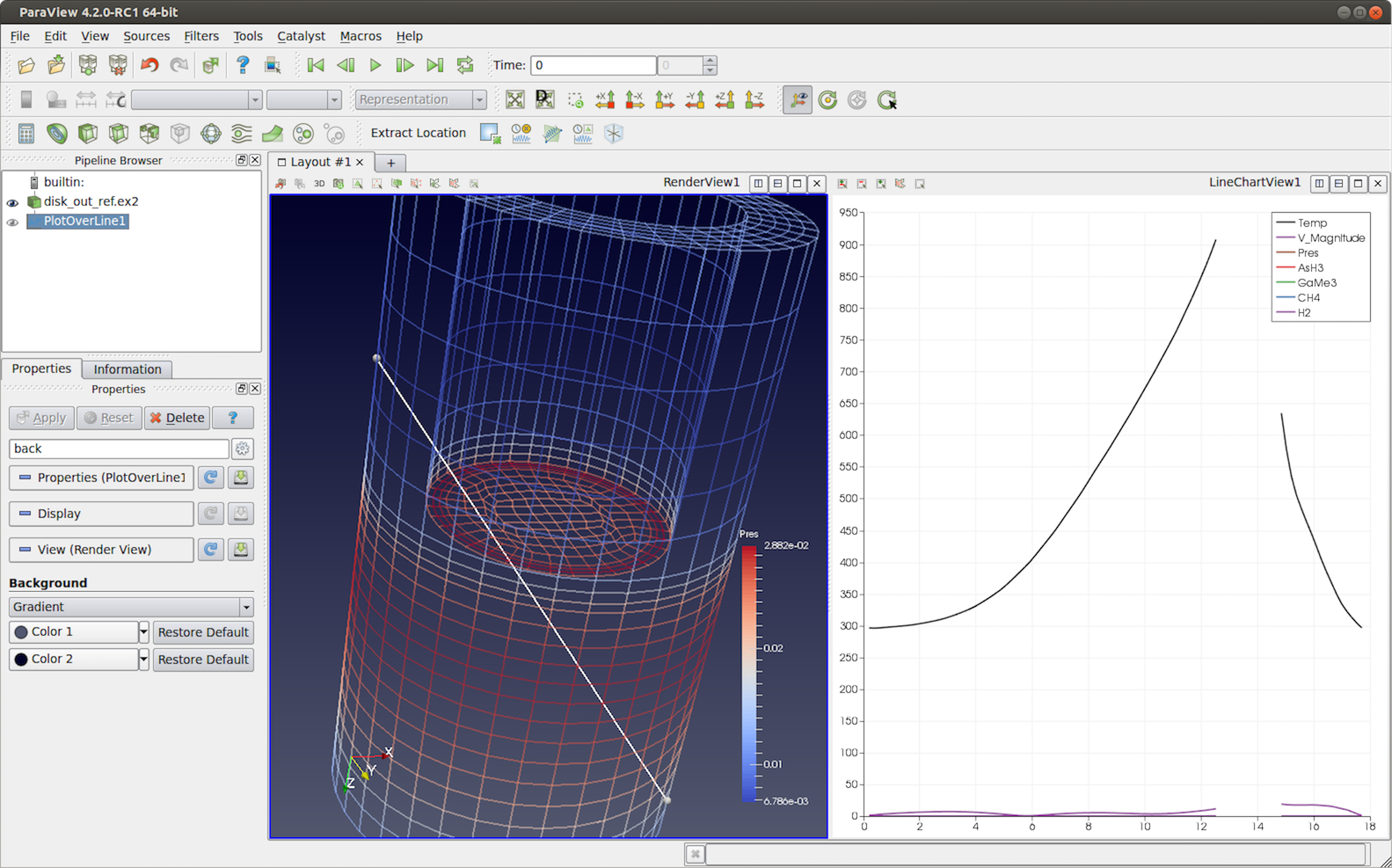
図 5.23 Plot Over Line フィルタを disk_out_ref.ex2 データセットに適用し、サンプリングされた位置の値を線に沿ってプロットします。ライン内のギャップは、ラインがデータセットの外側に位置する入力データセット内の位置に対応します。
Plot Over Line は、指定した行に沿って入力データセットをサンプリングし、その結果を Line Chart View に出力します。内部的には、このフィルタは Probe フィルタと同じメカニズムを使用し、ライン内の点に沿ってプローブし、含まれるセル属性と補間されたポイント属性を取得します。
Properties パネルの Resolution プロパティを使用すると、線に沿ったサンプルポイントの数を制御できます。
5.9. 属性操作に関するフィルタ
本節で説明するフィルタは、データセットに新しい属性配列を追加するために使用します。これは通常、パイプラインで使用して導出された量を追加して、さらに処理するために使用します。
5.9.1. Calculator
Calculator フィルタは、新しいデータ配列または新しい点座標を既存の入力配列の関数として計算します。新しいデータ配列の計算に点を中心とした配列を使用すると、結果の配列も点を中心とした配列になります。同様に、セル中心配列を用いた計算は、新しいセル中心配列を生成します。関数が点座標( Properties パネルの Coordinate Results プロパティをチェックして要求されました)を計算している場合、関数の結果は3成分のベクトルである必要があります。 Calculator インタフェースは、関数電卓と同様に動作します。評価する関数の作成時には、標準の操作順序が適用されます。各計算機能について説明します。特に明記しない限り、( と ) ボタンを使用してオペランドを括弧で囲みます。
Clear: 現在の関数を消去します。/: あるスカラーを別のスカラーで割ります。この関数のオペランドは、括弧で囲む必要はありません。*: 2つのスカラー値を乗算するか、ベクトルにスカラー値を乗算します(スカラー倍)。この関数のオペランドは、括弧で囲む必要はありません。-:スカラーまたはベクトルを減算(マイナス)するか、あるスカラーまたはベクトルを別のスカラーまたはベクトルから引きます。この関数のオペランドは、括弧で囲む必要はありません。+: 2つのスカラーまたは2つのベクトルを加算します。この関数のオペランドは、括弧で囲む必要はありません。iHat,jHat, andkHatは、それぞれX、Y、Z方向の単位ベクトルを表すベクトル定数です。sin(x): スカラーのサインを計算します。cos(x): スカラーのコサインを計算します。tan(x): スカラーのタンジェントを計算します。abs(x): スカラーの絶対値を計算します。sqrt(x): スカラーの平方根を計算します。asin(x): スカラーのアークサインを計算します。acos(x): スカラーのアークコサインを計算します。atan(x): スカラーのアークタンジェントを計算します。ceil(x): スカラーの上限を計算します。floor(x): スカラーの下限を計算します。sinh(x): スカラーの双曲線正弦を計算します。cosh(x): スカラーの双曲線余弦を計算します。tanh(x): スカラーの双曲線正接を計算します。x^y: あるスカラーを別のスカラーの累乗にします。この関数のオペランドは、括弧で囲む必要はありません。exp(x): \(e\) をスカラーのべき乗にします。dot(x, y): 2つのベクトルxとyの内積を計算します。mag(x): ベクトルの大きさを計算します。norm(x): ベクトルを正規化します。オペランドについて以下に説明します。0-9と小数点は、定数スカラー値を入力するために使用されます。ln(x): 基底 \(e\) に対するスカラーの対数を計算します。log10(x): 10を底とするスカラーの対数を計算します。
Calculator フィルターでは、ユーザーインターフェイスにボタンがない追加の操作を使用できます。
avg(x, y, z, ...): すべての入力引数の平均をとります。clamp(r0, x, r1): r0とr1の間の範囲でxを固定します。cross(x, y): 2つのベクトルの外積を計算します。equal(x, y): 正規化イプシロンによるxとyの等質性検定。erf(x): xのエラー関数。erfc(x): xの相補的なエラー関数。frac(x): xの小数部。hypot(x, y): xとyの斜辺、sqrt(x*x + y*y)に相当します。iclamp(r0, x, r1): 範囲r0とr1の外側にあるxを逆固定します。xが範囲内にある場合は、最も近い境界線にスナップします。inrange(r0, x, r1): xがr0とr1の範囲にあるとき、真を返します。log1p(x): 1+xの自然対数。ここでxは非常に小さい。log2(x): xの底2とする対数。logn(x, n): xの底nとする対数。ここでnは正の整数。min(x, y): 2つ以上のスカラーの最小値を計算します。max(x, y): 2つ以上のスカラーの最大値を計算します。mul(z, y, z, ...): すべての入力を掛け合わせます。ncdf(x): 正規累積分布関数。not_equal(x, y): 正規化イプシロンによるxとyの非同等性検定。pow(x, y): xをyのべき乗にします。root(x, n): xのn乗根。ここでnは正の整数。round(x): xを最も近い整数に丸めます。roundn(x, n): xを小数点以下n桁に丸めます。sgn(x): xの符号を計算します:x<0のとき-1、x>0のとき+1、それ以外は0。sum(x, y, z, ...): 全入力の合計値。trunc(x): xの整数部。acosh(x): ラジアン単位で表されるxの逆双曲線余弦。asinh(x): ラジアン単位で表されるxの逆双曲線正弦。atan2(x, y): ラジアン単位で表される(x / y)の双曲線正接。atanh(x): ラジアン単位で表されるxの逆双曲線正接。cot(x): xの余接。csc(x): xの余割。sec(x): xの正割。sinc(x): xのカーディナル・サイン。deg2rad(x): xを度数からラジアンへ変換します。deg2grad(x): xを度数から階数へ変換します。rad2deg(x): xをラジアンから度数に変換します。grad2deg(x): xを階数から度数に変換します。
以下のような等号・不等号があります。
==or=: xがyに厳密に等しい場合にのみ真。<>or!=: xがyと等しくないときのみ真。<: xがyより小さいときのみ真。<=: xがy以下のときのみ真。>: xがyより大きいときのみ真。>=: xがy以上のときのみ真。
以下の条件式とブーリアン演算子が使用できます。
if(x, y, z): xの評価値が真であればy、そうでなければz。true: 真の状態。false: 偽の状態。x and y: 論理積。xとyが共に真である場合にのみ真。mand(x, y, z, ...): 多入力論理積。すべての引数が真のときのみ真。mor(x, y, z, ...): 多入力論理和。いずれかの引数が真であれば真。x nand y: 否定論理積。xかyのどちらかが偽であるときのみ真。x nor y: 否定論理和。xもyも偽でないときのみ真。not x: 論理否定。入力された真偽値の反対を評価します。x or y: 論理和。xかyのどちらかが真であれば真。x xor y: 排他的論理和、xとyの論理状態が異なる場合のみ真。x xnor y: 両方の論理入力が同じである場合にのみ真。
Scalars メニューには、スカラー配列の名前と、点中心またはセル中心のデータのベクトル配列の構成要素がリストされます。 Vectors メニューには、点中心またはセル中心のベクトル配列の名前がリストされます。この関数は、各点(またはセル)について、その点における配列のスカラー値またはベクトル値(またはセル)を使用して計算されます。フィルタは任意のタイプのデータセットで動作しますが、入力データセットには少なくとも1つのスカラー配列またはベクトル配列が必要です。配列は、点中心またはセル中心にすることができます。 Calculator フィルタの出力は、入力と同じデータセットタイプです。
Did you know?
以前は、 Calculator フィルタで 3 つの入力スカラーをベクトル配列に変換するのが一般的な使用例でした。この場合、 Function は以下のようになります: \(scalar_x * iHat + scalar_y * jHat + scalar_z * kHat\).
現在、Merge Vector Components フィルタは、3つのスカラーを選択してベクトル配列に結合することだけの、より簡単な方法を提供します。
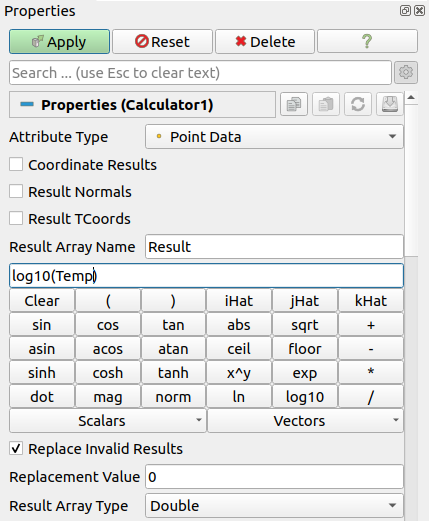
図 5.24 高度なプロパティを表示する Calculator フィルタに対する Properties パネル
Properties パネルでは、このフィルタのいくつかのオプションにアクセスできます。Coordinate Results 、 Result Normals 、または Result TCoords をチェックすると、計算された配列がそれぞれ点座標、法線、またはテクスチャ座標として設定されます。 Result Array Name は、計算結果の配列の名前を指定するために使用します。デフォルトは Result です。
式が無効な値を返すことがあります。すべての無効な値を特定の値に置き換えるには、 Replace Invalid Results チェックボックスをオンにし、無効な値の置き換えに使用する値を入力します Replacement Value 。出力配列のデータ型は、 Result Array Type プロパティで設定します。
式の再利用を容易にするために、式の読み込み、現在の式の保存、そして Expression Manager から既に保存されている式のリストを確認するための3つのヘルパーボタンも用意されています。
5.9.2. Expression Manager
ParaViewは式を保存して、式に素早くアクセスできるようにするための Expression Manager を提供し、式のプロパティの設定を容易にします。それぞれの式には名前を付けることができ、関連するグループを持つことができるので、Pythonの式を他の式から簡単にフィルタリングすることができます。
この機能は2つのパートに分かれています。
Property Panel からは、1行のプロパティテキスト入力が補強されています。
既存の表現にアクセスするためのドロップダウン・リスト
Save Current ExpressionボタンChoose Expressionダイアログへのショートカット
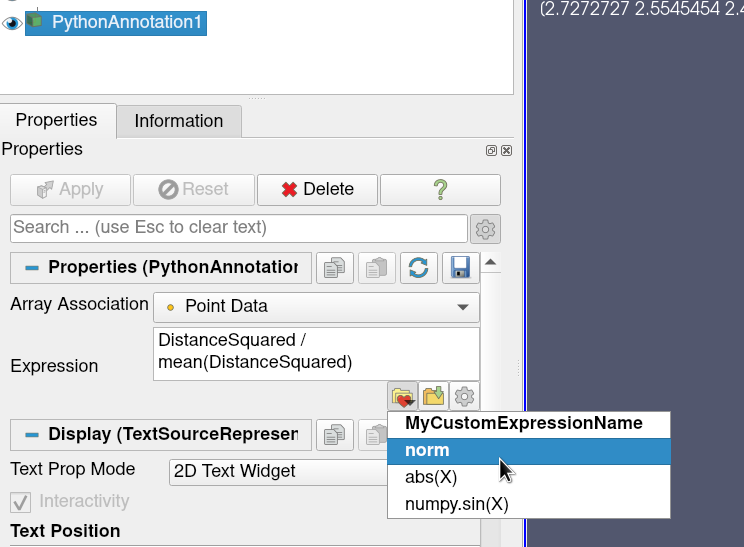
図 5.25 プロパティパネルの式関連ボタン。
Tools > Manage Expressions メニュー項目からもアクセスできる Choose Expression ダイアログは、保存されている式の編集および検索が可能なリストです。ParaViewは設定によってそれらの式を記録していますが、バックアップや共有のためにJSONファイルにエクスポートすることもできます。
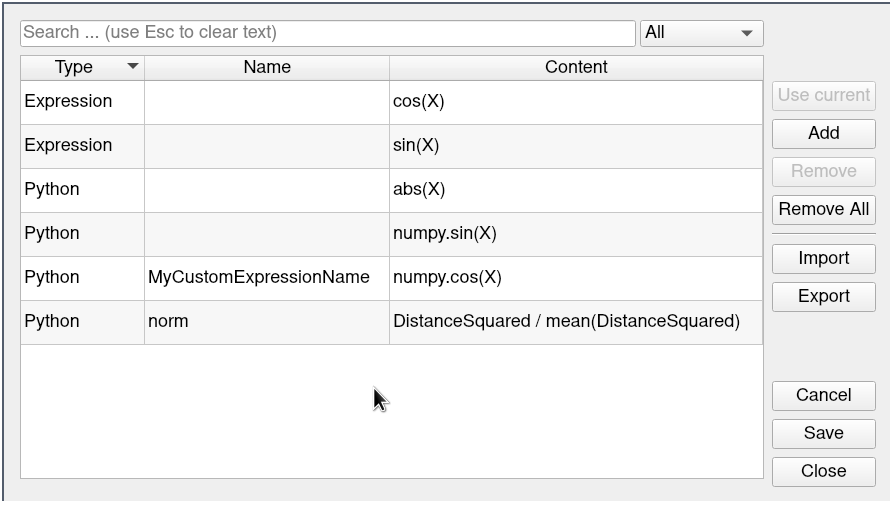
図 5.26 Expression Dialogを選択します。
5.9.3. Python calculator
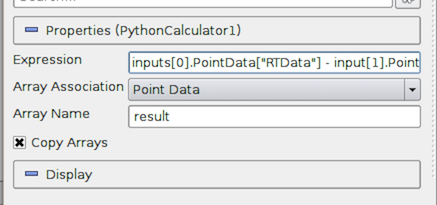
図 5.27 Python Calculator のプロパティパネル
Python Calculator は、ユーザーが指定した式に基づいて1つ以上の入力配列を処理し、新しい出力配列を生成するという点で、Calculator に似ています。ただし、計算にはPython (と NumPy)を使用します。そのため、より豊かな表現力を得ることができます。
使用する Expression 、配列の関連付けを示す Array Association ( Point Data または Cell Data )、出力配列の名前( Array Name )、入力配列を出力にコピーするかどうかを制御するトグル( Copy Array )を指定します。
Python Calculator`` は sec:ExpressionManager` で説明されている Expression Manager も統合しています。
5.9.3.1. 基本チュートリアル
最初に球ソースを作成し、Python Calculator を適用します。最初の式として、次の式を使用して適用します。
5
これにより、出力ポイントデータに配列名 result が作成されます。これは、各点の値が5の配列であることに注意してください。式の結果が1つの値になると、計算機は自動的に定数配列を作成します。次に、次の操作を実行します。
Normals
result 配列は、入力配列Normalsと同じである必要があります。詳細は後述しますが、calculatorにはさまざまな機能が用意されています。たとえば、次の式は有効です。
sin(Normals) + 5
Python Calculator は、Array Associationパラメータに応じて、点またはセルごとに1つの値を生成する必要があることに注意してください。ここで説明する関数のほとんどは、すべての点またはセルの値に個別に適用されます。入力と同じ次元の配列を生成します。しかし、min() や max() のように、単一の値を生成するものもあります。
Common Errors
Programmable Filter では、vtk.numpy_interface.algorithms は、スクリプトの実行前にインポートされます。その結果、min や max のようないくつかの組み込み関数は、そのインポートによって上書きされてしまいます。組み込み関数を使用するには、 import __builtin__ モジュールをインポートし、 __builtin__.min and __builtin__.max などでこれらの関数にアクセスします。
5.9.3.2. データへのアクセス
式内の入力配列にアクセスするには、いくつかの方法があります。最も簡単な方法は、名前でアクセスすることです。
sin(Normals) + 5
これは次の式と同じです。
sin(inputs[0].PointData['Normals']) + 5
上記の例では、いくつかの説明が必要です。ここで、 inputs[0] は、フィルタへの最初の入力(データセット)を参照します。 Python Calculator は、複数の入力を受け付けることができます。各入力には inputs[0] 、 inputs[1] 、 ...でアクセスできます。 .PointData または .CellData 修飾子を使用して、入力の点またはセルのデータにアクセスできます。その後、 [] 演算子を使用して、ポイントデータコンテナまたはセルデータコンテナ内の個々の配列にアクセスできます。配列名は必ず引用符または二重引用符で囲んでください。特定の文字(スペース、+、-、*、/ など)を含む名前を持つ配列には、このメソッドを使用しないとアクセスできません。
特定の関数は、入力メッシュに直接適用されます。これらのフィルタは、入力データセットを引数として受け取ります。たとえば、以下となります。
area(inputs[0])
点座標を明示的に定義するデータタイプの場合、 .Points 修飾子を使用して座標配列にアクセスできます。次の例では、座標配列の最初のコンポーネントを抽出します。
inputs[0].Points[:,0]
主にイメージデータ(一様直線格子)や直線格子などの特定のデータタイプでは、点座標は暗黙的に定義され、配列としてアクセスできないことに注意してください。
5.9.3.3. 複数データセットの比較
Python Calculator は、次の例に示すように、複数のデータセットの比較に使用できます。
メニューバーに移動し、File > Disconnect を選択してパイプラインをクリアします。
Source > Mandelbrot を選択し、適用をクリックすると、マンデルブロ セットのデフォルトバージョンが設定されます。この集合のデータは \(251 \times 251\) スカラー配列に格納されます。
もう一度 Source > Mandelbrot を選択してから、
Propertiesパネルに移動し、最大反復回数を50に設定します。Applyをクリックすると、同じサイズの配列で表されるマンデルブローセットの別のバージョンが設定されます。Shiftキーを押しながら、パイプラインインスペクタでマンデルブロの両方のエントリを選択してから、メニューバーに移動し、 Filter > Python Calculator を選択します。これで、2つのマンデルブロエントリは、
Python Calculatorの入力としてリンクされた状態で表示されます。Python Calculatorフィルタのプロパティパネルで、 Expression boxに次のように入力します。
inputs[1].PointData['Iterations'] - inputs[0].PointData['Iterations']
この式では、2番目と1番目のマンデルブロ配列の差を指定します。結果は
resultsという名前の新しい配列に保存されます。配列変数の名前の接頭辞inputs[1]とinputs[0]は、それぞれパイプラインの最初と2番目のマンデルブロエントリを参照します。PointDataは、入力にポイント値が含まれることを指定します。引用符で囲まれたラベル'Iterations'は、これらの配列のローカル名です。Applyをクリックして、計算を開始します。
Python Calculator に対して Properties Panel 内の Display タブをクリックし、 Color by ラベルの右側の最初のタブに移動します。そのタブでアイテムの結果を選択すると、右側の表示ウィンドウに Python Calculator に入力した式の結果が表示されます。2つのマンデルブロ配列の差を表すスカラー値は、現在のカラーマップ(詳細については、Edit Color Map...を参照)で設定されたカラーで表されます。
ここで次の点に注意してください。
Python Calculatorは、常に最初の入力から出力にメッシュをコピーします。すべての操作は、点ごとに適用されます。ほとんどの場合、入力メッシュ(トポロジとジオメトリ)が同じである必要があります。少なくとも、入力には同じ数の点とセルが必要です。
並列実行モードでは、入力はプロセス間で全く同じように分配されなければなりません。
5.9.3.4. 基本操作
Python Calculator は、\(+\)、 \(-\)、 \(*\)、 そして \(/\) 演算子を使用した基本的な算術演算をすべてサポートしています。これらは、スカラー、ベクトル、テンソルなどの点データとセルデータに、常に要素ごとに適用されます。これらの操作は、単一の値でも機能します。たとえば、次の例では、すべての法線のすべてのコンポーネントに5が追加されます。
Normals + 5
次の例では、1を最初のコンポーネントに、2を2番目のコンポーネントに、3を3番目のコンポーネントに追加します。
Normals + [1,2,3]
これは、単一の値を返す関数を混在させる場合に特に便利です。たとえば、次の例ではNormals配列を正規化しています。
(Normals - min(Normals))/(max(Normals) - min(Normals))
calculatorの一般的な使用例は、配列の1つのコンポーネントを操作する場合です。これは、次の方法で実行できます。
Normals[:, 0]
上式は、法線ベクトルの最初のコンポーネントを抽出します。ここで : は"all elements"のプレースホルダです。1つの要素を抽出するには、: をインデックスに置き換えます。たとえば、次の例では、最初の点の法線の最初のコンポーネントから定数配列を作成します。
Normals[0, 0]
または、次の例では、最初の点の法線をすべての点に割り当てます。
Normals[0, :]
make_vector() 関数を使用して、2つまたは3つのスカラー配列からベクトル配列を作成することもできます。
make_vector(velocity_x, velocity_y, velocity_z)
時間データセットの場合は、データセットの時間ステップインデックスまたは式の時間値 (それぞれ t_index または time_index 、 t_value または time_value ) にアクセスすることもできます。複数の入力を扱う場合、例えば inputs[0].t_index のように、適切な入力をスコープとする同じ変数名を指定することができます。
点の位置は、明示的な点の位置を定義するデータセットの Points 変数で利用できます。
一部のデータセットでは、フィールドデータは、セルまたは点に関連付けられていないグローバルデータ値を格納するために使用されます。Python Calculator の式でフィールドデータを使用するには、次の例に示すように、入力で使用可能な FieldData ディクショナリでデータにアクセスします。
VolumeOfCell * inputs[0].FieldData['MaterialData'][time_index]
Did you know?
暗黙的に Python Calculator はNumPyを使用します。式のすべての配列はNumPy配列と互換性があり、NumPy配列を使用できる場所で使用できます。これらの配列で何ができるかについての詳細は、NumPyのリファレンス [NumPydevelopers] を参照してください。
5.9.3.5. 関数
以下は、 Python Calculator で使用可能な関数のリストです。 ほとんどのNumPyおよびSciPy関数は Python Calculator で使用できるため、これは部分的なリストであることに注意してください。これらの関数の多くは、引数として単一の値または配列を取ることができます。
abs(x): \(x\) の絶対値を返します。add(x, y): 2つの値の合計を返します。\(x\) および \(y\) には、単一の値または配列を指定できます。これは \(x+y\) と同じです。area(dataset): メッシュ内の各セルの表面積を返します。aspect(dataset): メッシュ内の各セルのアスペクト比を返します。aspect_gamma(dataset): メッシュ内の各セルのアスペクト比ガンマを返します。condition(dataset): メッシュ内の各セルの条件番号を返します。cross(x, y): 2つの3Dベクトルの配列から、2つの3Dベクトルの外積を返します。curl(array): 3Dベクトルの配列のカールを返します。divergence(array): 3Dベクトルの配列の発散(divergence)を返します。divide(x, y): 要素ごとの分割。\(x\) および \(y\) には、単一の値または配列を指定できます。これは \(\frac{x}{y}\) と同じです。det(array): 2D正方行列の行列式を返します。determinant(array): 2D正方行列の行列式を返します。diagonal(dataset): データセットの各セルの対角線の長さを返します。dot(a1, a2): 2つのスカラー/ベクトル配列の2つのスカラー/ベクトルの内積を返します。eigenvalue(array): 2D正方行列の配列の固有値を返します。eigenvector(array): 2D正方行列の配列の固有ベクトルを返します。exp(x): \(e^x\) を返します。gradient(array): スカラーまたはベクトルの配列の勾配を返します。inv(array): 2D正方行列の逆行列を返します。inverse(array): 2D正方行列の逆行列を返します。jacobian(dataset): 2D正方行列の配列のjacobianを返します。laplacian(array): スカラー配列のラプラシアン(laplacian) を返します。ln(array): スカラー/ベクトル/テンソルの配列の自然対数を返します。log(array): スカラー/ベクトル/テンソルの配列の自然対数を返します。log10(array): スカラー/ベクトル/テンソルの配列の底が10の対数を(常用対数)返します。make_point_mask_from_NaNs(dataset, array): この関数はNaN値を持つ入力に対応するゴースト配列を生成します。各NaN値について、出力配列はvtk.vtkDataSetAttributes.HIDDENPOINT値に対応します。これらの値は、データセットが持つ可能性のあるゴースト値とも結合されます。make_cell_mask_from_NaNs(dataset, array): この関数はNaN値を持つ入力に対応するゴースト配列を生成します。各NaN値について、出力配列はvtk.vtkDataSetAttributes.HIDDENCELL値に対応します。これらの値は、データセットが持つ可能性のあるゴースト値とも結合されます。max(array): 配列の最大値を単一の値として返します。並列実行時にプロセス全体の最大値を計算します。max_angle(dataset): データセット内の各セルの最大角度を返します。mag(a): スカラー/ベクトルの配列の大きさを返します。mean(array): スカラー/ベクトル/テンソルの配列の平均値を返します。 並列実行時はプロセス全体の平均を計算します。min(array): 配列の最小値を単一の値として返します。並列実行時にプロセス全体の最小値を計算します。min_angle(dataset): データセット内の各セルの最小角度を返します。mod(x, y): remainder \((x, y)\) と同じです。multiply(x, y): \(x\) と \(y\) の積を返します。\(x\) および \(y\) には、単一の値または配列を指定できます。\(x\) と \(y\) が両方とも配列である場合、これは要素ごとの操作であることに注意してください。これは、\(x\times y\) と同じです。negative(x): \(-x\) と同じです。norm(a): スカラー/ベクトルの配列の正規化された値を返します。power(x, a): \(x\) と \(a\) の積です。ここで、\(x\) と \(a\) はどちらも単一の値または配列になります。\(x\) と \(a\) の両方が配列の場合、2つの配列間で1つずつマッピングが使用されます。reciprocal(x): \(\frac{1}{x}\) を返します。remainder(x, y): \(x-y\times floor (\frac{x}{y})\) を返します。\(x\) および:math:y には、単一の値または配列を指定できます。rint(x): \(x\) を最も近い整数に丸めます。shear(dataset): データセット内の各セルのせん断を返します。skew(dataset): データセットの各セルのスキューを返します。square(x): \(x*x\) を返します。sqrt(x): \(\sqrt[2]{x}\) を返します。strain(array): 3Dベクトルの配列の歪みを返します。subtract(x, y): 2つの値の差を返します。\(x\) および \(y\) には、単一の値または配列を指定できます。これは \(x-y\) と同じです。surface_normal(dataset): データセットの各セルのサーフェス法線を返します。trace(array): 2D正方行列の配列のトレースを返します。volume(dataset): データセットの各セルのボリューム法線を返します。vorticity(array): 3Dベクトルの配列の渦度/カールを返します。vertex_normal(dataset): データセット内の各点の頂点法線を返します。
5.9.3.6. 三角関数
以下は、サポートされている三角関数のリストです。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5.9.4. 勾配
Gradient フィルタは、あらゆる種類のデータセットにおいて、セルやポイントデータの配列の勾配を計算します。
非構造格子の場合、セルデータの勾配はセルの導関数に対応します。点データの場合、ある点での勾配は、その点が属するセルの導関数の平均として計算されます。
構造格子では、中心差分法を用いて勾配を計算します。ただし、データセットの境界では、境界要素に前進差分と後退差分を使用します。
このフィルタはオプションで、発散、渦度(カールとも呼ばれる)、Q基準を計算することができます。これらの量を計算するためには3成分の配列が必要です。初期設定では、勾配の計算のみが有効です。
均一直線格子( 3.1.3 章 参照) の場合には、点データ配列の勾配を効率的に計算する特定の実装も利用できます。この実装では,境界値を重複させた後に,境界要素での中心差分の使用を拡張しています。このオプションを有効にするには、 図 5.28 で示されているように、 Boundary Method プロパティを Smoothed に設定します。
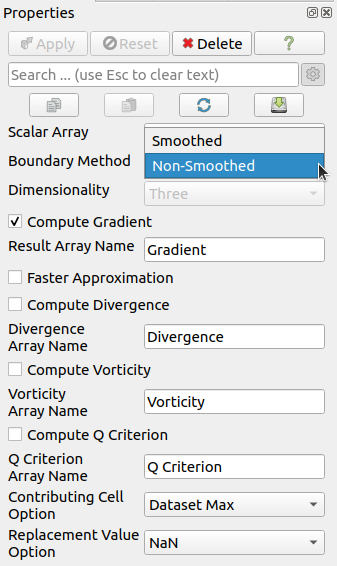
図 5.28 均一な構造格子に Gradient フィルタを適用した場合のプロパティパネル
5.9.5. Mesh Quality
Mesh Quality フィルタは、各セルの適応度の幾何学的尺度を含む新しいセル配列を作成します。セルの形状によって異なる品質基準を選択できます。
Triangle Quality は、三角形の品質を評価するために使用する品質尺度を示します。 Radius Ratio は、三角形の3つの頂点で囲まれた円のサイズを、三角形の3つのエッジに接する円のサイズで割った値です。 Edge Ratio は、最長エッジ長と最短エッジ長の比率です。
Quad Quality は、クアッドセルの評価に使用する品質尺度を示します。
Tet Quality は、四面体の品質を評価するために使用する品質尺度を示します。 Radius Ratio は、四面体の4つの頂点によって囲まれる球のサイズを、四面体の4つのフェースに接する円のサイズで割ったものです。 Edge Ratio は、最長エッジ長と最短エッジ長の比率です。 Collapse Ratio は、反対側の三角形の上にある頂点の高さの最小比率を、すべての頂点/三角形のペアにまたがる反対側の三角形の最長エッジで割った値です。
HexQualityMeasure は、六面体セルの品質を評価するために使用される品質尺度を示します。
5.10. White-boxフィルタ
これには、 Programmable Filter および Programmable Source が含まれます。これらのフィルタ/ソースには、データの生成や処理を行うPythonコードを追加できます。これらのためのPythonコードの書き方については、5 章 で説明します。
5.11. Favoriteフィルタ
複数のフィルタを使用する場合は、Filters > Favorites メニューでフィルタを整理できます。これは、パイプラインのコンテキストメニューから、または 図 5.29 に示すように Filters > Manage Favorites メニューから実行できます。このダイアログでは、カテゴリとサブカテゴリを作成できます。フィルタやカテゴリの並べ替えや移動を行うためのドラッグ & ドロップ操作をサポートしています。また、Favorites は、サポートされているプラットフォームの他のフィルタサブメニューで強調表示されます。お気に入りはユーザ設定に保存され、他のParaViewセッションで使用できます。
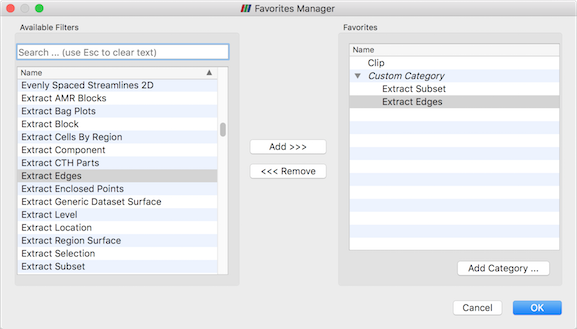
図 5.29 Favorites Managerダイアログ。左:使用可能なフィルタのリスト。右:カテゴリ別に整理されたお気に入り。
5.12. ベストプラクティス
5.12.1. データの爆発的増加の回避
ParaView で表示されるパイプラインモデルは、探索的な可視化に非常に便利です。コンポーネント間の疎結合により、独自の可視化を構築するための非常に柔軟なフレームワークが提供され、パイプライン構造により、パラメータをすばやく簡単に調整できます。
この結合の欠点は、より大きなメモリフットプリントを有することができることです。 このパイプラインの各ステージは、データの独自のコピーを保持します。可能な限り、ParaView はデータの浅いコピーを実行し、パイプラインの異なるステージがメモリ内の同じデータブロックを指すようにします。ただし、新しいデータを作成したり、データの値やトポロジを変更するフィルタでは、結果用に新しいメモリを割り当てる必要があります。ParaView が非常に大きなメッシュをフィルタリングしている場合、フィルタを不適切に使用すると、使用可能なすべてのメモリがすぐに枯渇する可能性があります。 したがって、大規模データセットを可視化する場合、フィルタのメモリ要件を理解することが重要です。
以下のアドバイスは、非常に大量のデータを扱い、残りのメモリが不足している場合のためのものです。メモリ不足の危険がない場合は、次のアドバイスは関係ありません。
構造データを扱うときには、どのフィルタがデータを非構造データに変更するかを知ることが非常に重要です。非構造データは、トポロジを明示的に書き出す必要があるため、セルあたりのメモリ使用量が構造データよりもはるかに多くなります。ParaView には、トポロジを何らかの方法で変更する多数のフィルタがあります。これらのフィルタは、生成されるすべてのタイプのトポロジを処理する唯一のデータセットであるため、非構造格子としてデータを書き出します。次のフィルタのリストは、新しい非構造トポロジをその出力に書き出します。これは入力とほぼ同じです。
Append Datasets |
Extract Edges |
Subdivide |
Append Geometry |
Linear Extrusion |
Tessellate |
Clean |
Loop Subdivision |
Tetrahedralize |
Clean to Grid |
Reflect |
Triangle Strips |
Connectivity |
Rotational Extrusion |
Triangulate |
D3 |
Shrink |
|
Delaunay 2D/3D |
Smooth |
技術的には、Ribbon フィルタと Tube フィルタはこのリストに含まれます。 ただし、ポリゴンデータの1Dセルでしか機能しないため、通常は入力データは小さく、ほとんど問題になりません。
このようなフィルタのセットは、非構造格子も出力しますが、このデータの一部を削減する傾向があります。ただし、このデータ削減量は、多くの場合、非構造データへの変換によるオーバーヘッドよりも小さいことに注意してください。また、削減のバランスがよくとれていない場合が多いことにも注意してください。単一のプロセスでセルが失われない可能性があります(よくあります)。したがって、これらのフィルタは、非構造データには注意し、構造データには細心の注意を払って使用する必要があります。
Clip |
Extract Selection |
Decimate |
Quadric Clustering |
Extract Cells by Region |
Threshold |
上記のリストの項目と同様に、Extract Subset はデータを実行します。 構造データセットの削減だけでなく、構造データセットも出力します。したがって、新しいデータの作成に関する警告は引き続き適用されますが、非構造格子への変換について心配する必要はありません。
この次のフィルタセットでは、非構造データも出力されますが、データの次元が縮小されるため(例:3Dから2D)、出力が大幅に小さくなります。したがって、これらのフィルタは通常、非構造データで使用しても安全であり、構造データでは多少の注意が必要です。
Cell Centers |
Feature Edges |
Contour |
Mask Points |
Extract CTH Fragments |
Outline (curvilinear) |
Extract CTH Parts |
Slice |
Extract Surface |
Stream Tracer |
次のフィルタでは、データの接続はまったく変更されません。代わりに、データにフィールド配列を追加するだけです。既存のデータはすべてシャローコピーされます。 これらのフィルタは通常、すべてのデータに対して安全に使用できます。
Block Scalars |
Octree Depth Scalars |
Calculator |
Point Data to Cell Data |
Cell Data to Point Data |
Process Id Scalars |
Curvature |
Random Vectors |
Elevation |
Resample with dataset |
Generate Surface Normals |
Surface Flow |
Gradient |
Surface Vectors |
Level Scalars |
Texture Map to... |
Median |
Transform |
Mesh Quality |
Warp (scalar) |
Octree Depth Limit |
Warp (vector) |
この最終的なフィルタのセットは、出力にデータを追加しないか(重要なデータはすべてシャローコピーされる)、または追加されるデータは一般に入力のサイズに依存しません。これらはほとんどの場合、どんな状況(時間はかかりますが)でも追加しても安全です。
Annotate Time |
Outline |
Append Attributes |
Outline Corners |
Extract Block |
Plot Global Variables Over Time |
Extract Datasets |
Plot Over Line |
Extract Level |
Plot Selection Over Time |
Glyph |
Probe Location |
Group Datasets |
Temporal Shift Scale |
Histogram |
Temporal Snap-to-Time-Steps |
Integrate Variables |
Temporal Statistics |
Normal Glyphs |
これまでのクラスには当てはまらない特殊なケースのフィルタがいくつかあります。現在、 Temporal Interpolator および Particle Tracer などの一部のフィルタでは、時間の経過に伴うデータの変化に基づいて計算が実行されます。 したがって、これらのフィルタは、2つ以上の時間インスタンスのデータをロードする必要があり、メモリ内で必要とされるデータ量を2倍以上にすることができます。 Temporal Cache フィルタは、複数のtimeインスタンスのデータも保持します。時間統計(Temporal Statistics)などの時間フィルタや、時間の経過とともにプロットされるフィルタでは、ディスクからすべてのデータを繰り返しロードする必要がある場合があることに注意してください。 このため、余分なメモリを必要としない場合でも、非常に長い時間がかかることがあります。
Programmable Filter も、分類できない特殊なケースです。このフィルタはプログラムされている処理を実行するので、これらのカテゴリのいずれにも分類できます。
5.12.2. 不要データの除去
大規模なデータを処理する場合は、可能な限りデータを選別し、できるだけ早く処理することをお勧めします。大規模なデータのほとんどは3Dジオメトリから始まり、必要なジオメトリは多くの場合サーフェスです。通常、サーフェスは非常に小さいので、メモリフットプリントは、派生元のボリュームよりも早い段階でサーフェスに変換することをお勧めします。そうすれば、比較的安全に他のフィルタを適用することができます。
非常に一般的な可視化操作は、等高線(Contour)フィルタを使用して、ボリュームから等値面を抽出することです。 Contour フィルタは通常、入力よりもかなり小さいジオメトリを出力します。したがって、 Contour フィルタを使用する場合は、早期に適用する必要があります。 Contour フィルタにパラメータを設定する場合は、多くの等値面の値を指定した場合に発生する可能性がある大量のデータを生成できるため、注意が必要です。等値面の周囲のノイズなどの高周波数によっても、大きく不規則なサーフェスが形成される場合があります。
ボリュームの内部をピアするもう1つの方法は、ボリュームに対して Slice を実行することです。 Slice フィルタは、ボリュームを平面と交差させ、平面が交差するボリューム内のデータを確認できるようにします。大規模なデータセット内の対象フィーチャの相対的な位置がわかっている場合は、スライスすることをお勧めします。
データの a priori 知識がほとんどなく、データセット全体の長いメモリと処理時間なしにデータを探索したい場合は、 Extract Subset フィルタを使用してデータをサブサンプルできます。サブサンプリングされたデータは、元のデータよりも大幅に小さくなる可能性がありますが、ロードバランスが良好である必要があります。もちろん、サブサンプリングが小さなフィーチャをまたいでしまうと、それらを見逃してしまう可能性があることに注意してください。また、フィーチャを見つけたら、戻って完全なデータセットで可視化する必要があります。
ボリュームのサブセットを取り出すことができる機能もいくつかあります。 Clip 、 Threshold 、 Extract Selection 、および Extract Subset はすべて、何らかの基準に基づいてセルを取り出すことができます。しかし、抽出されたセルはほとんどバランスがとれていないことに注意してください。いくつかのプロセスではセルが削除されていないことが予想されます。 Extract Subset を除くすべてのフィルタは、構造データ型を非構造格子に変換します。したがって、抽出されたセルの大きさがソースデータの大きさよりも1桁以上小さい場合を除いて、使用しないでください。
可能な場合は、3Dデータを抽出するフィルタの使用を、2Dサーフェスを抽出するフィルタに置き換えます。たとえば、データを通過する平面が必要な場合は、 Clip フィルタではなく Slice フィルタを使用します。特定の範囲の値を含むセル領域の位置を知りたい場合は、 Threshold フィルタを使用してすべてのセルを抽出するのではなく、 Contour フィルタを使用して範囲の最後にサーフェスを生成することを検討してください。フィルタを置き換えると、下流のフィルタに影響を与える可能性があることに注意してください。たとえば、 Threshold の後に Histogram フィルタを実行すると、ほぼ同等の Contour フィルタの後に実行した場合とはまったく異なる結果になります。