4. 大規模モデルの可視化
ParaView は、Sandia国立研究所などで、ここに示した例を含む世界最大のスーパーコンピュータ上で実行される大規模シミュレーションのデータを可視化するために頻繁に使用されています。
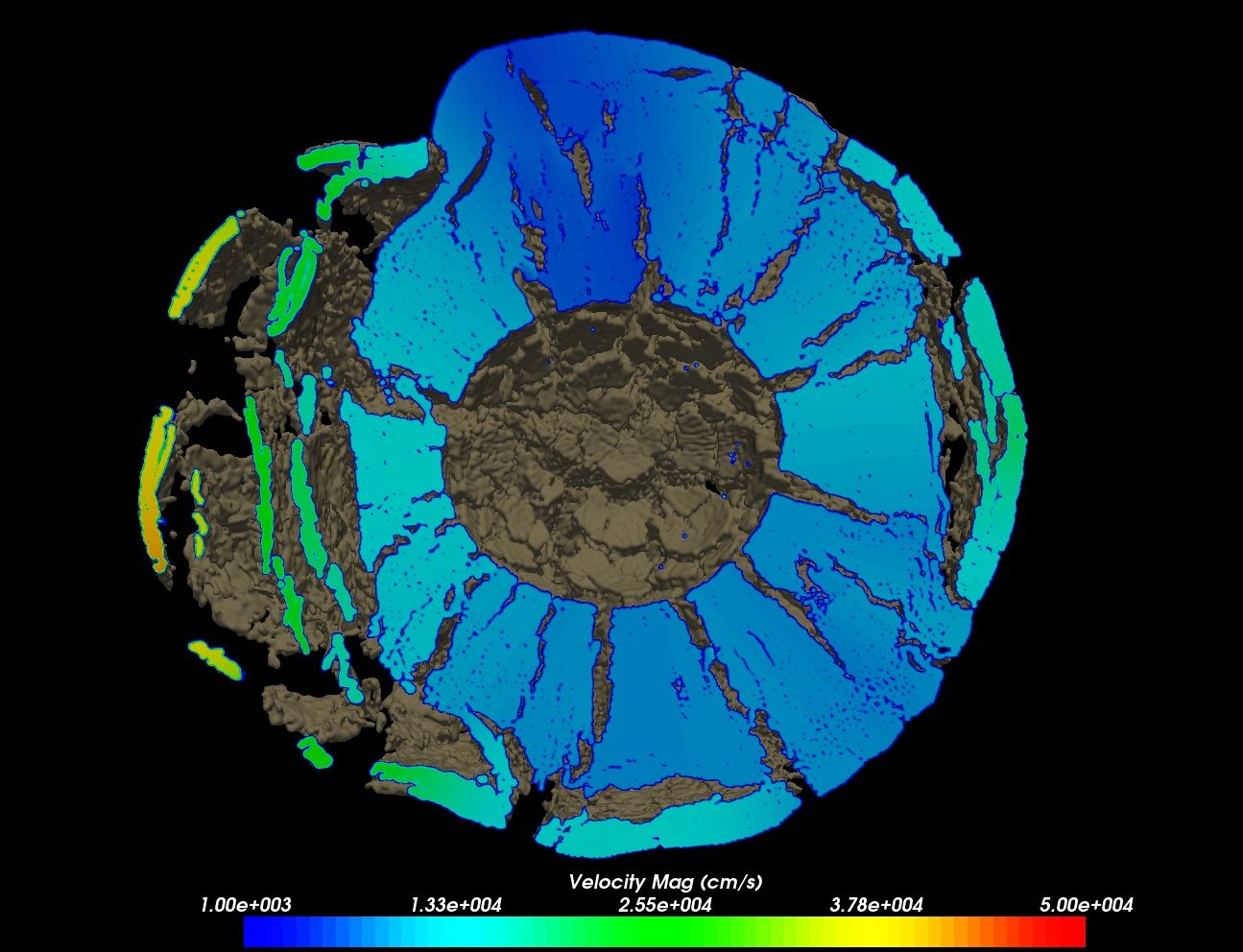
図 4.29 小惑星「ゴレフカ」の中心で爆発した10メガトン級の衝撃を10億セル以上のCTH衝撃物理シミュレーションで再現。

図 4.30 高緯度で極空気を閉じ込める周極ジェットである極渦の崩壊をモデル化する10億個のセルを使用したSEAM気候モデリングシミュレーション。
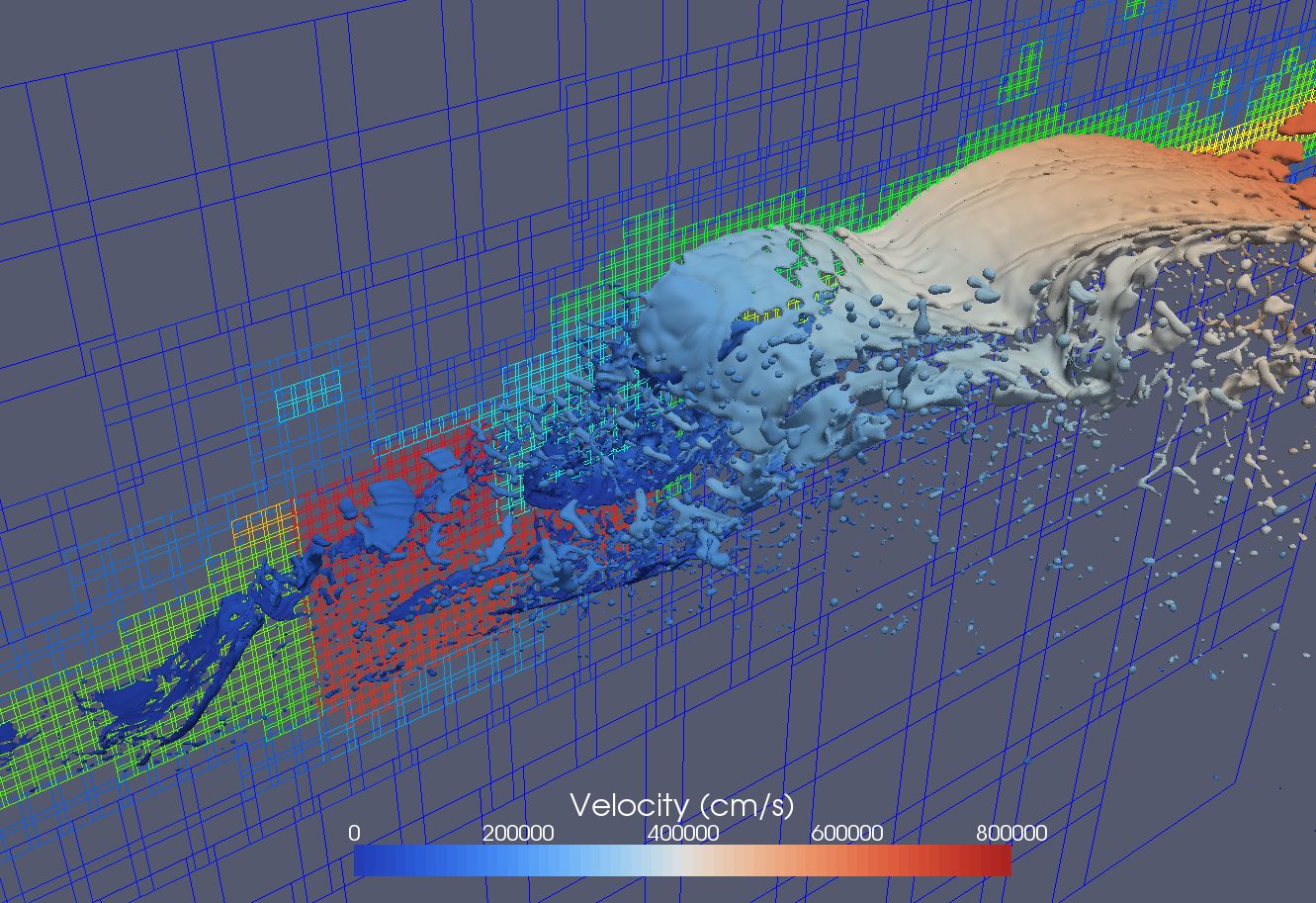
図 4.31 AMRデータを生成するCTHシミュレーション。 ParaView は、数十億のセル、数十万のブロック、および11レベルの階層(図示せず)で構成されるCTHシミュレーションAMRデータを可視化するために使用されています。

図 4.32 33億個の構造セルとの磁気リコネクションのVPICシミュレーション。 画像提供:ビルドートン、ロスアラモス国立研究所。
図 4.33 合成ジェットが非定常クロスフロージェットを発行するフルウィング上の流れをシミュレートする33億の四面体メッシュを生成した大規模な現場PHASTAシミュレーション(16万MPIプロセスで実行)。

図 4.34 偏向した翼の後流を模擬した13億個の要素メッシュを生成した大規模なin-situ PHASTAシミュレーション(25.6万MPIプロセスで実行)。画像提供:Michel Rasquin, Argonne National Laboratory
本節では、ParaView の並列可視化機能を使用して、このような大きなメッシュを可視化することについて説明します。このセクションでは、いくつかの演習がありますが、前節よりも ”ハンズオン” でありません。主に、大規模な並列可視化を行うために必要な概念的な知識を学びます。演習では、並列マシン上で ParaView を実行するために必要な基本的なテクニックを説明します。
最も基本的な考え方は、大規模なマシン上で実行する場合、各ノードがデータセット全体の異なる領域を同時に処理することです。従って、実行可能なデータ解像度はマシンの総メモリ容量によって制限される。ここでは、基本的な ParaView アーキテクチャと並列アルゴリズムについて説明し、この知識をどのように適用するかを示します。
4.1. 並列可視化アルゴリズム
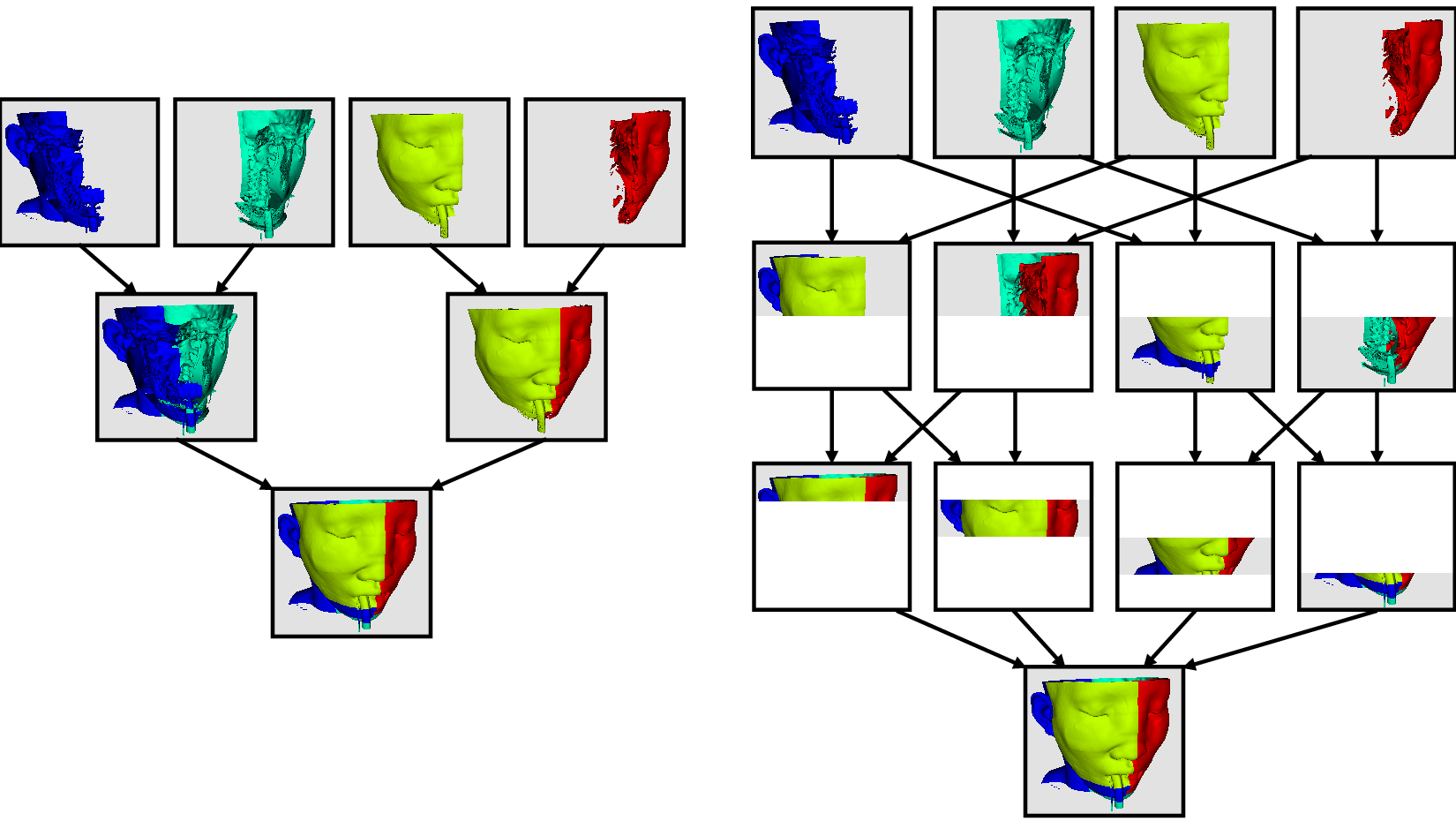
可視化では幸いなことに、多くの演算が簡単に並列化できます。私たちが扱うデータはメッシュの中に入っています。つまり、データはすでにセルによって小さな断片に分割されているのです。まずセルを各プロセスに分割することで、分散型並列機で可視化を行うことができるのです。説明のために、非常に単純化されたメッシュを考えてみましょう。
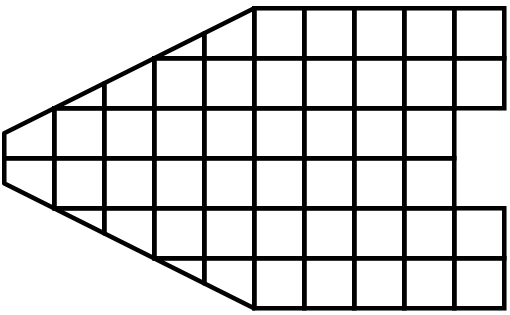
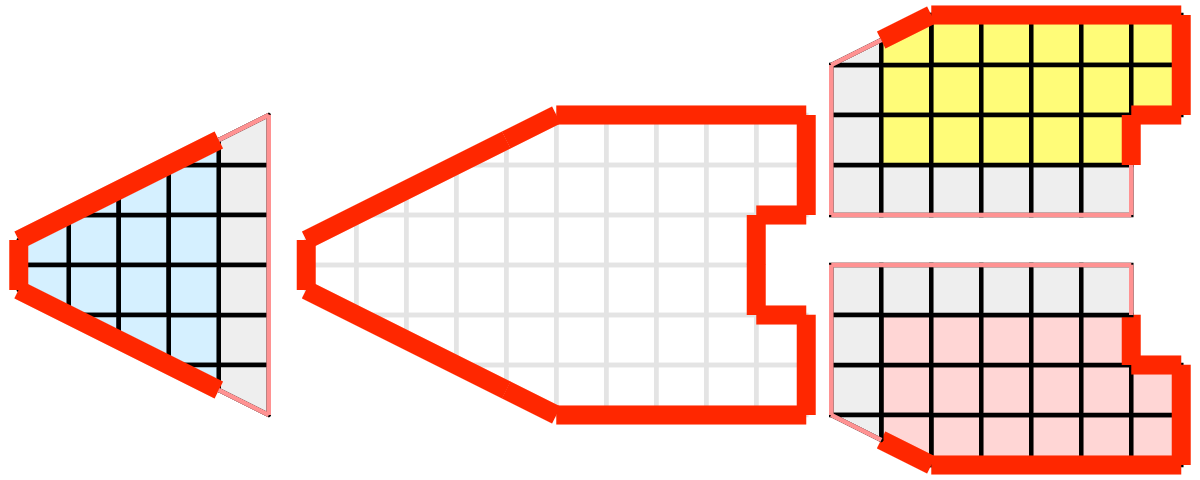
さて、このメッシュに対して、3つの処理で可視化を行いたいとします。下図のようにメッシュのセルを青、黄、ピンクの領域で分割することができます。
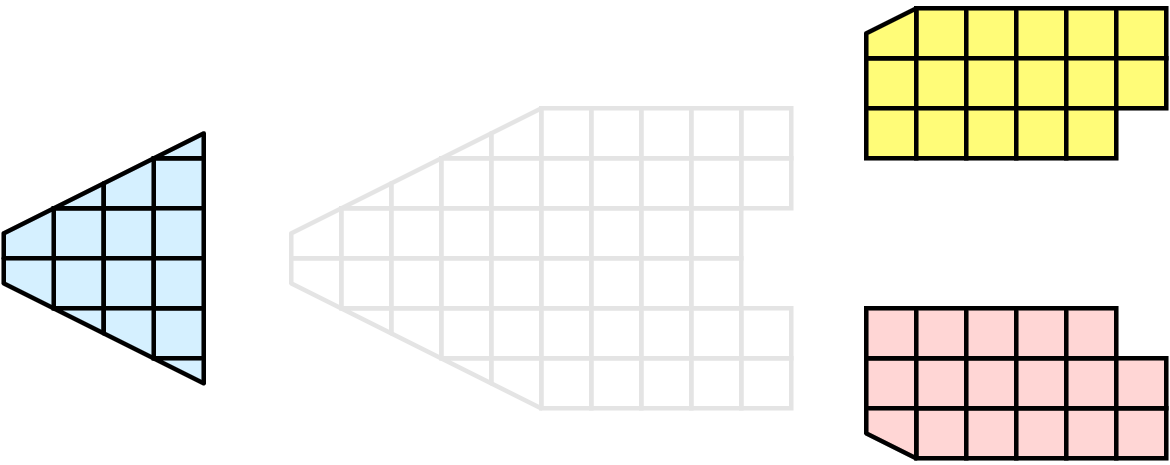
一旦パーティション化されると、多くの可視化アルゴリズムは、各プロセスが独立してそのローカルなセルのコレクションに対してアルゴリズムを実行することで動作するようになります。例えば、クリッピング(これは 練習 2.11 を含む複数の演習で実証されています)を考えてみましょう。クリッピング平面を定義して、その同じ平面を各プロセスに与えるとします。
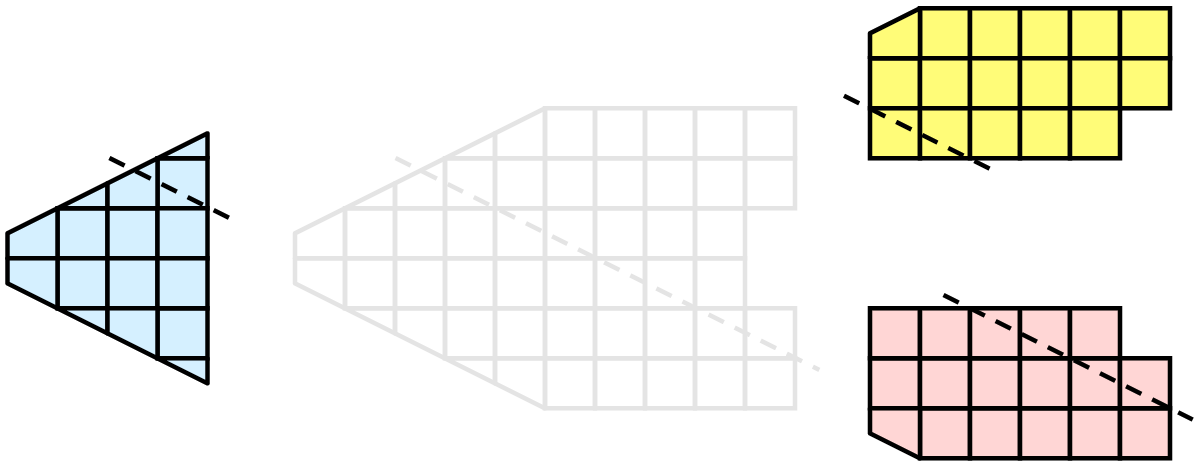
各プロセスは、この平面でセルを個別にクリップできます。 最終的な結果は、クリッピングを連続して行った場合と同じです。 セルをまとめると(明らかな理由で大きなデータに対して実際に行うことはありません)、クリッピング操作が正しく行われたことがわかります。
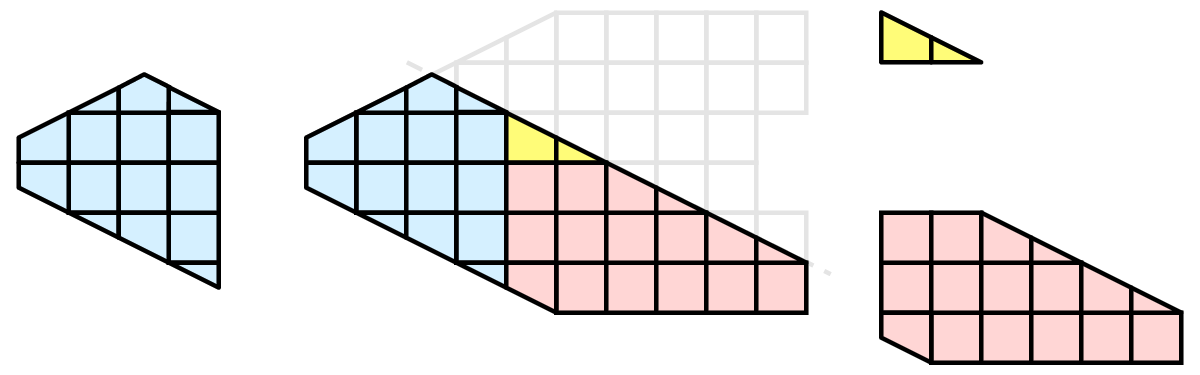
このように、多くの、しかし全ての操作が自明な並列化可能なものではありません。その他の操作は、 4.7.2 章 で説明されているゴーストレイヤーが利用可能であれば、簡単に並列化することができます。また、ノード間でより広範なデータ共有が必要な処理もあります。これらのフィルタでは、ParaView はマシンのノード間で通信するためにMPIに頼ります。
4.2. 基本的な並列レンダリング
並列可視化を行う際には、レンダリングプロセスまでのすべてのプロセスでデータのパーティショニングが保たれるように配慮しています。ParaView は IceT と呼ばれる並列レンダリングライブラリを使用します。IceTは、並列レンダリングに sort-last アルゴリズムを使用します。この並列レンダリングアルゴリズムでは、各プロセスが独立してジオメトリのパーティションをレンダリングし、部分画像を コンポジット して最終画像を形成します。
前図は簡略化したものです。IceTには、バイナリツリー、バイナリスワップ、radix-k など、複数のフェーズで効率的に作業を分担する並列画像合成アルゴリズムが搭載されています。
ソートラスト並列レンダリングの素晴らしいところは、その効率がレンダリングされるデータ量に全く影響されないことです。そのため、非常にスケーラブルなアルゴリズムであり、大きなデータにも適しています。ただし、並列レンダリングのオーバーヘッドは、画像のピクセル数に応じて直線的に増加します。これは、例えば、ParaView でタイル表示壁を駆動するときに問題になることがあります。したがって、この章で後述するレンダリングパラメータのいくつかは、画像サイズの制限を扱っています。
パラレルレンダリングにはオーバーヘッドがあるため、ParaView はシリアルにレンダリングすることもでき、可視データが十分に小さいときに自動的にレンダリングされます。可視メッシュがユーザー定義の閾値設定より小さい場合、または並列レンダリングがオフまたは利用できない場合、ジオメトリは表示ノードに送られ、ローカルにラスタライズされます。明らかに、これはレンダリングされるデータが小さいときにのみ行われるべきで、そうでなければレンダリングプロセスが圧倒されます。
4.3. ParaViewアーキテクチャ
このように並列可視化について紹介しましたが、ParaView がどのように構成され、どのように上記の並列タスクをオーケストレーションしているかについて知っておくと役に立ちます。
ParaView は、3層のクライアントサーバーアーキテクチャとして設計されています。ParaView の3つの論理ユニットは次のとおりです。
- Data Server
データの読み込み、フィルタリング、書き込みを担当するユニットです。パイプラインブラウザで見ることができるパイプラインオブジェクトは、すべてデータサーバーに含まれています。データサーバーは、並列で使用することができます。
- Render Server
レンダリングを担当するユニット。レンダーサーバーは並列にすることもでき、その場合はビルトインの並列レンダリングも有効になります。
- Client
可視化の確立を担当するユニット。クライアントは、サーバーにおけるオブジェクトの生成、実行、破棄を制御するが、データは一切含みません(したがって、サーバーはクライアントをボトルネックとせずに拡張することができます)。GUIがある場合は、それもクライアントに含まれます。クライアントは常にシリアルアプリケーションです。
これらの論理ユニットは物理的に分離されている必要はない。論理ユニットはしばしば同じアプリケーションに組み込まれ、それらの間の通信の必要性を排除しています。ParaView を実行するには3つのモードがあります。どのモードで ParaView を実行しても、 2 章 と 3 章 で学んだユーザーインターフェースとスクリプトAPIはほとんど変更されないことに注意してください。
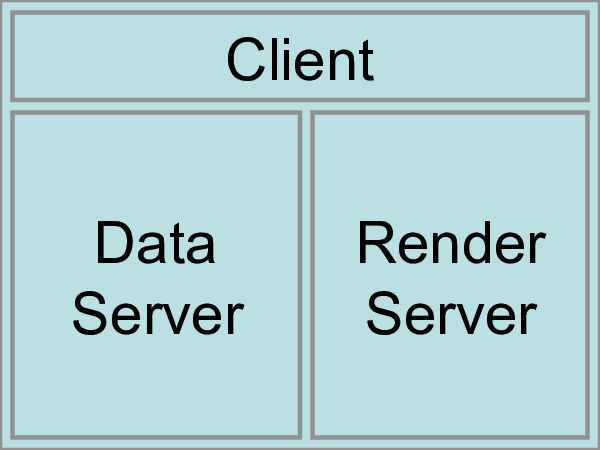
最初のモードは、すでにお馴染みの スタンドアロン モードです。スタンドアロンモードでは、クライアント、データサーバー、レンダーサーバーがすべて1つのシリアルアプリケーションに統合されています。パラビュー(paraview)アプリケーションを実行すると、自動的に ビルトイン サーバーに接続され、パラビューの全機能を使用する準備ができます。
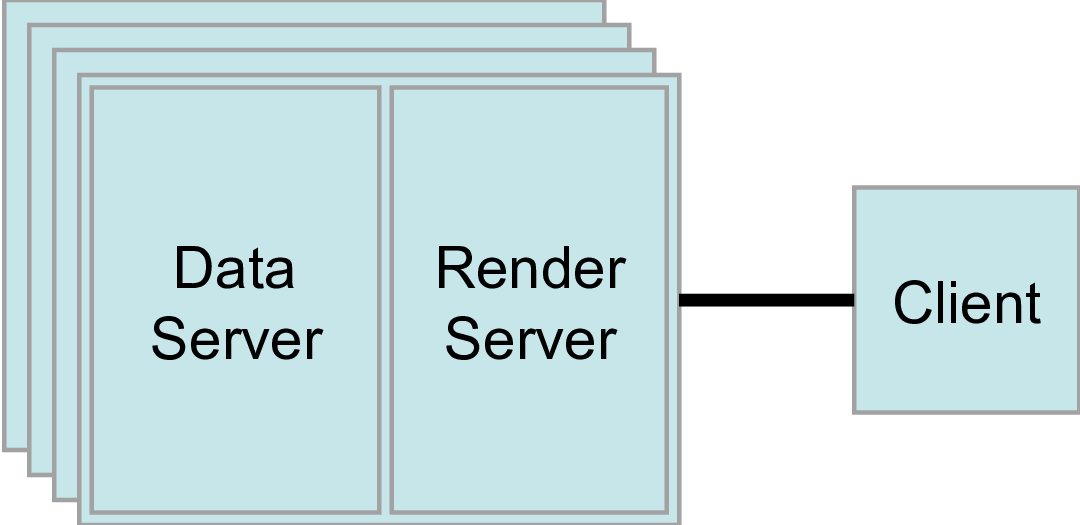
2つ目のモードは、クライアント・サーバー モードです。クライアント・サーバーモードでは、並列マシン上で pvserver プログラムを実行し、paraview クライアントアプリケーションでそれに接続します。pvserver プログラムはデータサーバとレンダリングサーバの両方を内蔵しており、データ処理とレンダリングの両方がそこで行われます。クライアントとサーバーはソケットで接続されていますが、これは比較的遅い通信モードであると想定されるため、このソケットでのデータ転送は最小限にとどめています。
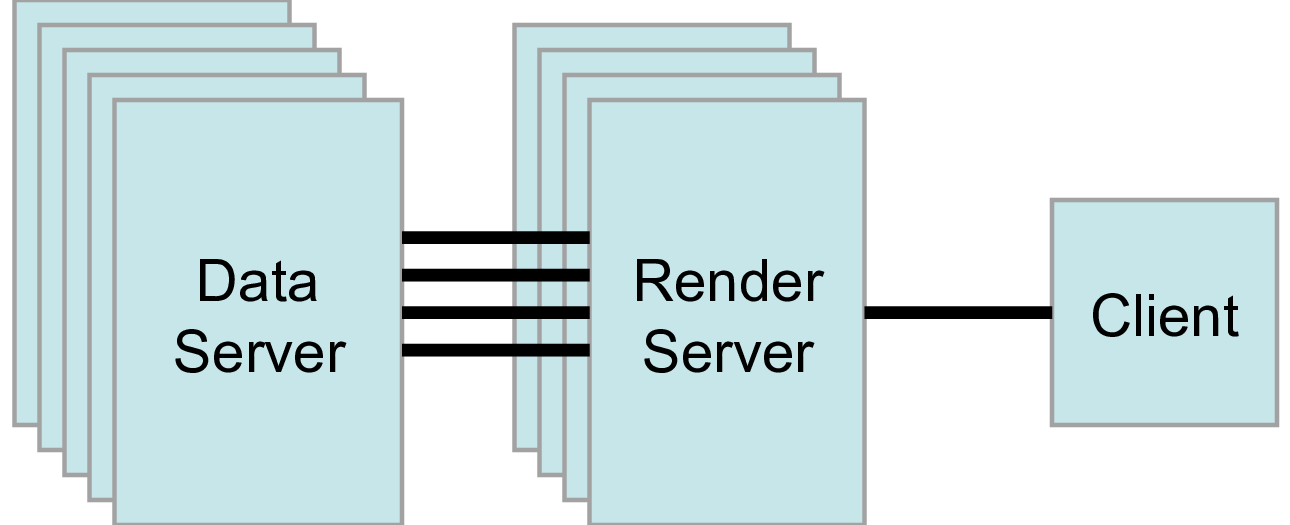
3つ目のモードは、クライアントレンダー・サーバー・データサーバー モードである。このモードでは、3つの論理ユニットがすべて別々のプログラムで実行されます。従来通り、クライアントは1つのソケット接続でレンダーサーバーに接続されます。レンダーサーバーとデータサーバーは、レンダーサーバー内の各プロセスごとに多数のソケット接続で接続されています。ソケットを介したデータ転送は最小限に抑えられている。
クライアント-レンダー-サーバー-データサーバーモードはサポートされていますが、私たちはほとんどこれを使用することをお勧めしません。このモードの本来の目的は、大規模で強力な計算プラットフォームと、グラフィックスハードウェアを搭載した小規模な並列マシンが存在するような異種環境を活用することです。しかし、実際には、データサーバーからレンダーサーバーにジオメトリを移動するのにかかる時間が、その利点をほとんど上回ると思われます。計算プラットフォームがグラフィックスクラスタよりもはるかに大きい場合は、大規模な計算プラットフォームでソフトウェアレンダリングを使用します。2つのプラットフォームのサイズがほぼ同じであれば、すべての計算をグラフィックスクラスタで実行します。
4.4. 並列ParaViewサーバーにアクセスする
Accessing a standalone installation of ParaView is trivial. Download and install a pre-compiled binary or get it from your package manager, and go. To visualize extreme scale results, you need to access an installation of ParaView, built with the MPI components enabled, on a machine with sufficient aggregate memory to hold the entire dataset and derived data products. Accessing a parallel enabled installation of ParaView’s server is intrinsically harder than accessing a standalone version.
最近のKitware社の ParaView のバイナリ配布は、Mac、Linux、そしてオプションでWindows用のMPIを含んでいます。WindowsのMPI対応バイナリは、MicrosoftのMPIに依存しており、別途インストールする必要があります。このチュートリアルの残りの部分では、これらをカバーしませんが、ParaView メーリングリストに遠慮なく質問してください。
バイナリにバンドルされている特定のMPIライブラリのバージョンは、可能な限り広い互換性のために選択されていることに注意してください。実稼働環境では、マシンのネットワークファブリック用に調整されたMPIバージョンでコンパイルすると、ParaView はより効果的になります。システム管理者は、どのMPIバージョンを使用するかを決める手助けをしてくれるでしょう。
並列機で ParaView をコンパイルするためには、お客様またはシステム管理者の方が以下のものを必要とします。
CMake クロスプラットフォームビルドセットアップツール https://www.cmake.org
MPI
OpenGLは、オンスクリーン(X11)またはオフスクリーン(EGL)モードでGPUを使用するか、Mesaを介してソフトウェアで使用することができます。
Python +NumPy +Matplotlib (すべてオプションですが、強く推奨します)
Qt \(\ge\) 4.7 (オプション)
オプションのライブラリなしでコンパイルすると、ある機能が使用できなくなります。QtなしでコンパイルすることはGUIアプリケーションが使えないことを意味し、Pythonなしでコンパイルすることはスクリプトが使えないことを意味します。NumPyはPythonそのものと同じくらい重要であり、Matplotlibは数値テキストやある種のビュー、カラールックアップテーブルに役立ちます。
ParaView をコンパイルするには、まずCMakeを実行し、コンパイルパラメータを設定し、システム上のライブラリを指すようにします。これで、ParaView をビルドするために使用するmakeファイルが作成されます。ParaView サーバーの構築の詳細については、ParaView Wikiを参照してください。
https://www.paraview.org/Wiki/Setting_up_a_ParaView_Server#Compiling
クロスコンパイルを必要とするHPCクラスのマシンや、クラウドベースのオンデマンドシステムなど、特殊なマシンで ParaView をコンパイルすることは、困難な作業となる可能性があります。ParaView メーリングリストでの無料アドバイスや、キットウェア社との契約によるサポートが受けられます。
幸いなことに、ParaView がすでにインストールされている大規模なシステムが多数あります。もし幸運にもこれらのシステムの一つでアカウントを持っているならば、何もコンパイルする必要はないはずです。ParaView コミュニティは、システム固有のドキュメントへのポインタを持つこれらのopt inリストを ParaView Wikiで管理しています。もし、システムメンテナが許可されれば、このリストに追加することをお勧めします。
https://www.paraview.org/Wiki/ParaView/HPC_Installations
また、ParaView を並列に実行することは、スタンドアロンクライアントを実行するよりも本質的に困難です。リモートコンピュータへのログイン、並列ノードの割り当て、並列プログラムの起動、そして時にはファイアウォールを通過して計算ノードへの対話的接続を確立することなどです。これらのステップについては、次の2つの節で詳しく説明し、最終的に理論から実践的な演習に戻ります。
4.5. バッチ処理
3 章 で紹介した ParaView の Python スクリプトインターフェースは、オフラインで実行可能で、人間がループから除外され、本質的に再現可能であるという重要な性質があります。
大規模なシステムでは、マスターしなければならない2つのステップがあります。1つ目は、MPIを通して ParaView を並列に実行することです。2つ目は、システムのキューイングシステムを通してジョブを投入することです。どちらのステップも、マシンによって構文が異なるので、詳細はシステムのドキュメントを参照してください。
手元にあるPCクラスのシステムで、Kitwareのバイナリを並列実行するという最も単純なケースで、 ParaView を並列実行する方法を説明します。
練習 4.1 (Running a visualization script in parallel)
MPI並列プログラムを起動するための mpiexec プログラム、 pvbatch 実行ファイル、Pythonスクリプトの3つが必要です。
Pythonスクリプトでは、各ノードが単純な多角形の球体の一部を、ジョブ内のプロセス数に応じて変化するカラーマップで描画する例を考えてみます。
from paraview.simple import *
sphere = Sphere()
rep = Show()
ColorBy(rep, ("POINTS", "vtkProcessId"))
Render()
rep.RescaleTransferFunctionToDataRange(True)
Render()
WriteImage("parasphere.png")
エディターを使って、このスクリプトを parasphere.py というファイルに入力し、どこかに保存してください。このスクリプトは、並行して行われた ParaView セッションで記録された、Sources → Sphere を作成し、vtkProcessId 配列を色づけに使用しました。
実行ファイルについては、ParaView に付属しているものを使用することにしましょう。Kitwareの ParaView バイナリをインストールすると、mpiexec と pvbatch が以下の場所にあります:
Macでは:
/Applications/ParaView-x.x.x.app/Contents/MacOS/mpiexecそして
/Applications/ParaView-x.x.x.app/Contents/bin/pvbatchLinuxの場合、バイナリを/usr/localに展開したと仮定しています:
/usr/local/lib/paraview-x.x.x/mpiexecそして
/usr/local/bin/pvbatchなお、ParaView に付属するmpiを使うには、ParaView のlibディレクトリ(/usr/local/lib/paraview-x.x.x)をLD_LIBRARY_PATHに追加する必要があることにご注意ください。
Windowsで、ParaView の “MPI” バージョンと、MS-MPI ソフトウェア(Microsoft から別途無料で入手可能)をインストールしたと仮定しています。
C:/Program Files/Microsoft MPI/Bin/mpiexecそして
C:/Program Files/ParaView x.x.x/bin/pvbatch
ここで、コマンドラインから次のように発行して、スクリプトを並列に実行します。
Macでは:
/Applications/ParaView-x.x.x.app/Contents/MacOS/mpiexec -np 4 /Applications/ParaView-x.x.x.app/Contents/bin/pvbatch parasphere.pyLinuxでは:
/usr/local/lib/paraview-x.x.x/mpiexec -np 4 /usr/local/bin/pvbatch parasphere.pyWindowsでは:
mpiexec -np 4 "C:/Program Files/ParaView x.x.x/bin/pvbatch" parasphere.py
ParaView が一瞬実行され、デスクトップにウィンドウが表示されるかもしれませんし、表示されないかもしれません。いずれにせよ、次のようなparasphere.pngという名前のファイルができていることでしょう:

システムのキューイング・システムを通じてジョブを投入するには、通常、コマンドラインで次のようなコマンドを発行します。
qsub -A <project name to charge to compute time to> \
-N <number of nodes> \
-n <number of processors on each node> \
mpiexec -np <N*n> \
pvbatch <arguments for pvbatch> \
script_to_execute.py <arguments for Python script>
このコマンドは、マシン上に要求された数の計算ノードを予約し、将来ノードが使用できるようになった時に、MPIジョブを生成します。MPIジョブは、ParaView のPythonスクリプトサーバーを並列に実行し、与えられたスクリプトを処理するように指示します。
多くのキューイングシステム、mpi の実装、サイト固有のポリシーがあります。したがって、ここですべてのシステムで動作する正確な構文を提供することは不可能です。システム管理者に指示を仰いでください。一旦、構文がわかれば、上記の球の例を実行して、システムが動作しているかどうかを判断できるはずです。
4.6. インタラクティブな並列処理
大規模なデータセットを扱う日常的な作業では、インタラクティブな可視化を並列で行うことも可能です。このモードでは、データが処理されているHPCリソースから遠く離れたワークステーションで ParaView GUIを使って作業しながら、動的にデータを調査し、可視化パイプラインを修正することができます。
インタラクティブな構成では、データ処理とレンダリング部分が上記のように並行して動作しますが、Pythonスクリプトの代わりに ParaView GUIから制御されます。
サーバープロセスの起動は上記と同様ですが、pvbatch 実行ファイルを使用する代わりに、pvserver 実行ファイルを使用します。前者は Python スクリプトからコマンドを受け取ることに限定され、後者はリモート ParaView GUI プログラムからコマンドを受け取るように構築されています。
クライアントとサーバーの接続は、paraview クライアントアプリケーションを通じて確立されます。サーバーへの接続とサーバーからの切断は、 と
と  のボタンで行います。ParaView が起動すると、自動的に組み込みサーバーに接続されます。また、サーバーから を切断するたびに、builtin に接続されます。
のボタンで行います。ParaView が起動すると、自動的に組み込みサーバーに接続されます。また、サーバーから を切断するたびに、builtin に接続されます。
ボタンを押すと、ParaView は、接続可能な既知のサーバーのリストを含むダイアログボックスを表示します。このサーバーのリストは、サイト固有とユーザー固有の両方が可能です。
サーバーへの接続方法は、GUIでAdd Serverボタンを押すか、XML定義ファイルで指定することができます。サーバー接続の指定にはいくつかのオプションがありますが、最終的には、サーバーを起動するコマンドと、起動後に接続するホストを ParaView に指定することになります。
もう一度、Kitwareのバイナリを使ったデモを行い、構文が大きく異なる大規模なシステムで必要な手順の概要を説明します。
練習 4.2 (Interactive Parallel Visualization)
The pvserver executable can be found in the same directory as the
pvbatch executable. Let us begin by running it in parallel.
Macでは:
/Applications/ParaView-x.x.x.app/Contents/MacOS/mpiexec -np 4 /Applications/ParaView-x.x.x.app/Contents/bin/pvserver &Linuxでは:
/usr/local/lib/paraview-x.x.x/mpiexec -np 4 /usr/local/bin/pvserver &Windowsでは:
mpiexec -np 4 ^ "C:/Program Files/ParaView x.x.x/bin/pvserver"
次に、ParaView GUI を起動し、 ボタンをクリックします。これにより、Choose Server Configurationダイアログボックスが表示され、サーバー接続パスのダウンロードや作成、または定義済みのパスへの接続を行うことができます。
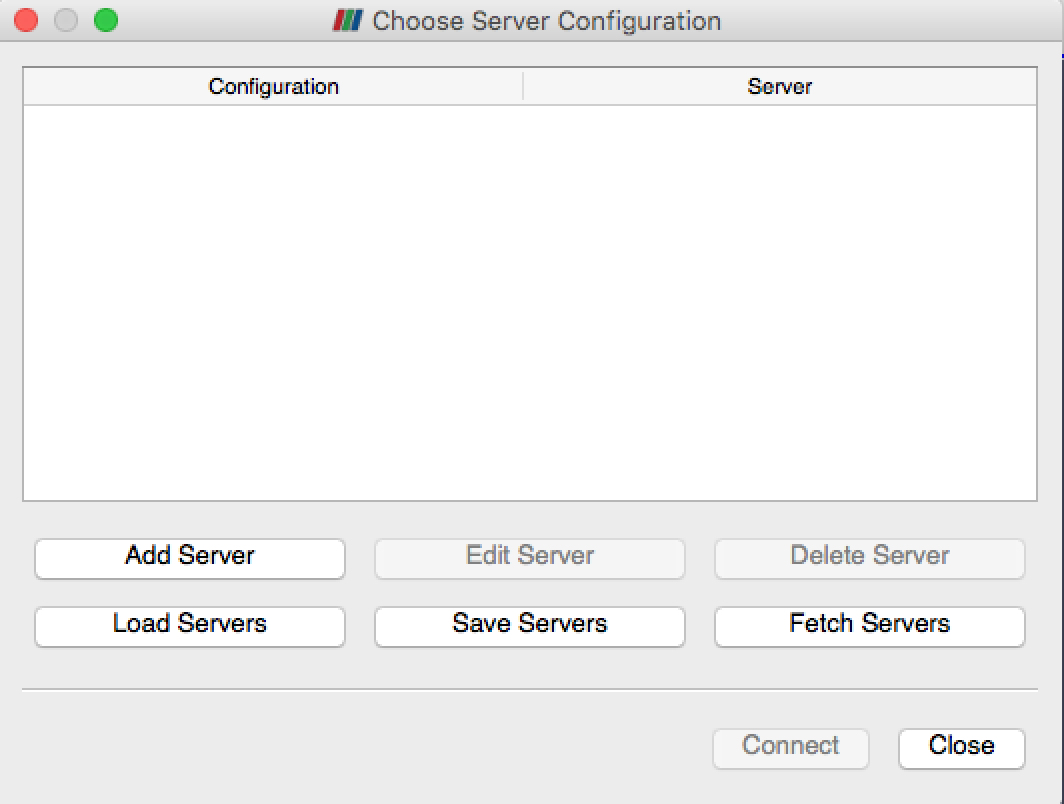
ここで、Add Server ボタンをクリックして新しいパスを作成し、ローカルマシンで動作している待機中の pvserver に接続するよう構築します。
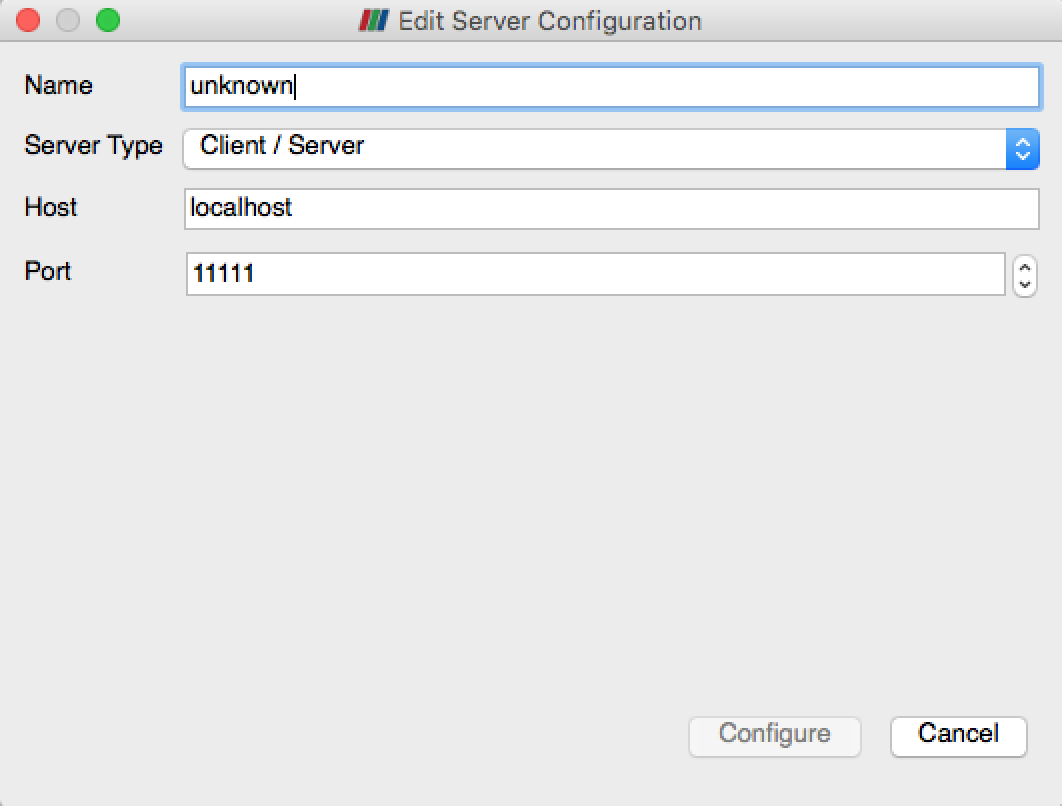
サーバー設定の編集ダイアログで、接続パスの名前を “unknown” から “my computer” に変更します。実際の使用では、接続するリモートマシンのニックネームとIPアドレスを入力することになります。ここでConfigureボタンを押します。
サーバー起動設定の編集ダイアログで、待機中の pvserver をすでに起動しているので、起動の種類を Manual のままにします。実際の使用では、通常 Command を使用し、リモートマシン上でサーバーを起動するスクリプトをダイアログに入力します。ダイアログのSaveをクリックして、接続の定義を完了します。
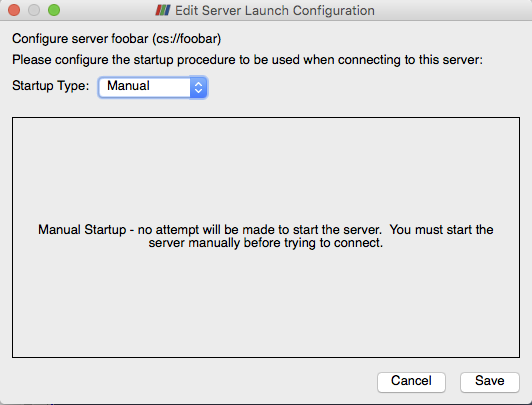
connection を定義すると、 を押すたびに、Choose Server Configuration ダイアログに表示されます。 接続の名前(この場合は “my computer”)をクリックして、Connect をクリックすると、GUI と pvserver の間の接続が確立されます。
Once connected, simply File → Open files on the remote system and work with them as before. To complete the exercise, open or create a dataset, and choose the vtkProcessId array to examine how it is partitioned across the distributed memory of the server.
実際には、リモートマシン上で並列サーバーを立ち上げ、それに接続する構文はより複雑になります。典型的な手順は、リモートマシンのログインノードに ssh を実行して、ある数のノードを要求するスクリプトを実行するジョブを投入し、それらのノードで MPI で pvserver を実行し、少なくとも 1 ホップの ssh トンネルを介して (上記の逆ではなく) 待っているクライアントに戻って接続するよう pvserver が作られることです。システム管理者やその他の冒険好きな人たちは、ここで詳細を見つけることができます:
https://www.paraview.org/Wiki/Setting_up_a_ParaView_Server#Running_the_Server
https://www.paraview.org/Wiki/Reverse_connection_and_port_forwarding
ローカルマシンでは、ヘルパーユーティリティも必要かもしれません。MacのXQuartz(X11用)とWindowsのPutty(ssh用)は、リモート接続を開始するのに便利です。これらは、次の演習を完了するために必要です。
接続が確立されたら、その手順をスクリプトや設定ファイルに保存しておく必要があります。システム管理者は、許可されたユーザーが簡単にダウンロードして使用できるように、これらを公開することができます。これらの設定ファイルのいくつかは、ParaView のウェブサイトでホストされており、ParaView のクライアントはそこからダウンロードすることができます。
練習 4.3 (Fetching and using Connections)
もう一度、 をクリックして、Choose Server Configuration ダイアログを表示させます。今回は、Fetch Servers ボタンを押してください。これにより、Fetch Server Configurationsダイアログボックスが表示され、Webサイトからのサーバー定義のリストが表示されます。一つを選んで、Import Selected ボタンをクリックし、それを ParaView 環境設定にダウンロードします。新しい接続は、 “my computer” への接続と同じように利用できるようになりました。
リモートマシンを使用するには、もう一回 をクリックします。今回は “my machine” ではなく、新しいマシンを選択し、Connect をクリックします。そうすると、Connection Options for ...ダイアログボックスが表示され、パラレルセッションのパラメータを入力することができるようになります。
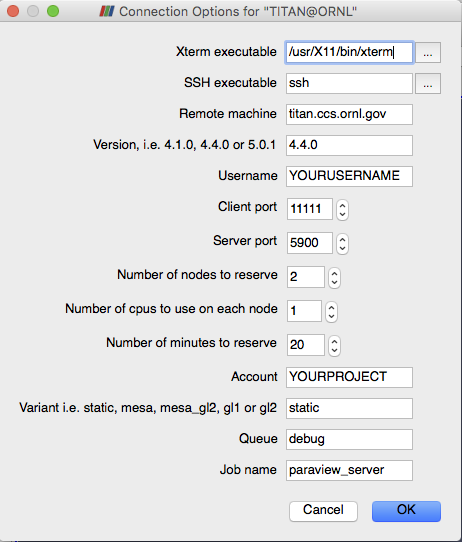
設定するパラメータには、リモートマシンのユーザー名、予約するノードとプロセスの数、およびそれらを予約する時間の長さが含まれます。各サイトには、サーバー上の起動スクリプトに渡される追加の選択肢があるかもしれません。設定後、OKをクリックして、接続を確立します。
OKをクリックすると、ParaViewは通常ターミナルウィンドウ(MacとLinuxではxterm、Windowsではcmd.exe)を起動します。ここで、実際にリモートマシンにアクセスするための認証情報を入力する必要があります。ログオンすると、ノードを予約するスクリプトが自動的に実行され、ほとんどの場合、ターミナルセッションには、リモートシステムのキューを見るためのオプションのメニューがあります。ジョブがキューのトップに到達すると、ParaView 3D Viewウィンドウが戻り、今度はリモートマシンの容量を手元に置いて、リモート可視化を開始することができます。
4.7. 並列データ処理の実用化
4.7.1. メモリの管理
非常に大きなモデルを扱う場合、コンピュータのメモリ使用量を追跡することが重要です。大規模なモデルで発生する最も一般的で苛立たしい問題の1つは、メモリが不足することです。非常に大きなモデルを扱う場合、コンピュータのメモリ使用量を追跡することが重要です。非常に大きなモデルを扱う場合、コンピュータのメモリ使用量を把握しておくことが重要です。大きなモデルで発生する最も一般的でイライラする問題の1つは、メモリ不足です。これは、仮想メモリシステムでのスラッシングや、プログラムのフォールトにつながります。
4.8.2 章 と 4.8.3 章 は、メモリの使用量を減らすための提案をしています。それでも、システムで利用可能なメモリに目を光らせておくことは賢明です。ParaView は、まさにそのために設計された memory inspector と呼ばれるツールを提供します。
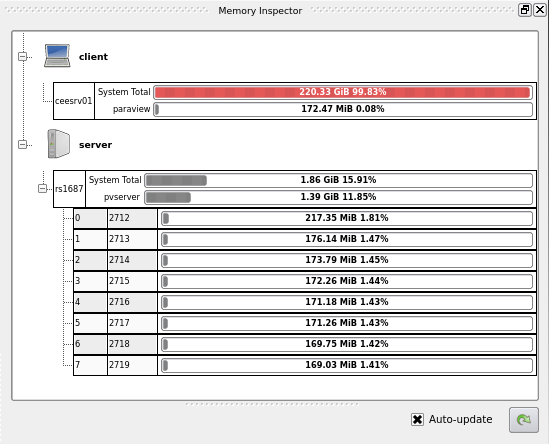
メモリインスペクタにアクセスするには、メニューバーのView → Memory Inspectorを選択します。メモリインスペクタは、実行中のクライアントと、接続されているサーバーの両方の情報を提供します。システムで使用されているメモリの総量と、ParaView が使用しているメモリの量が表示されます。複数のノードを含むサーバーの場合、コングロマリット・ジョブと各ノードの両方の情報が提供されます。1つのノードでメモリの問題が発生すると、ParaView ジョブ全体に問題が発生する可能性があることに注意してください。
4.7.2. ゴーストレベル
残念ながら、セルのパーティションに対して可視化アルゴリズムをやみくもに実行しても、必ずしも正しい答えが得られるとは限らない。簡単な例として、external faces アルゴリズムを考えてみましょう。external faces アルゴリズムは、1つのセルにのみ属するすべてのセル面を見つけ、それによってメッシュの境界を特定します。パーティションに対してexternal facesを独立に実行するとどうなるでしょうか。

おっと。すべてのプロセスが独立して外側の面のアルゴリズムを実行したとき、多くの内部の面が誤って外側の面であると認識されたことがわかります。これは、あるパーティションのセルが、別のパーティションに隣接している場合に起こります。プロセスは他のパーティションのセルにアクセスできないので、これらの隣接セルが存在することを知る術はありません。
ParaView や他の並列可視化システムで採用されている解決策は、ghost cell (halo regions とも呼ばれる) を使用することです。ゴースト・セルとは、あるプロセスで保持されてますが、実際には別のプロセスに属しているセルのことになります。ゴーストセルを利用するには、まず、各パーティションで隣接するセルをすべて特定する必要があります。次に、これらの隣接セルをパーティションにコピーし、以下の例でグレーで示したようにゴーストセルとしてマークします。
ゴースト・セルを使って 外側のフェイスアルゴリズムを実行すると、内側のフェイスを外側と誤認していることが分かります。しかし、これらの誤判定された顔はすべてゴースト・セル上にあり、顔はそれが来たセルのゴースト状態を継承します。 次に、ParaView はゴースト・フェイスを取り除き、正しい答えが残ります。
この例では、ゴースト・セルの1つのレイヤーを表示しています。ParaView は複数層のゴーストセルを取得することもできます。各層には、下位のゴースト層や元のデータ自体にまだ含まれていない、前の層の隣接セルが含まれます。これは、それぞれがゴーストセルの独自の層を必要とするカスケード・フィルタがある場合に便利です。各フィルタは、上流からゴーストセルの追加レイヤーを要求し、データからレイヤーを削除してから下流に送ります。
4.7.3. データパーティショニング
ほとんどの場合、ParaView はデータを分割する作業を、そのデータを生成したシミュレーションコードに任せます。そして、ParaView の特定のリーダーモジュールの責任で、問題のファイル形式を効率的に動作させるために、通常は異なるノードから異なるファイルを独立して同時に読み取ります。理想的なケースでは、並列パイプラインの残りの部分も独立して同時に動作します。
しかし、一般的なケースでは、データを分割して分散させるので、データの分割方法の影響に対処することが賢明です。4.1 章 で示されたデータは 空間的に一貫した パーティショニングがなされています。つまり、各パーティションのすべてのセルは、空間のコンパクトな領域に配置されています。データを分割する方法は他にもあります。例えば、ランダムなパーティショニングが考えられます。
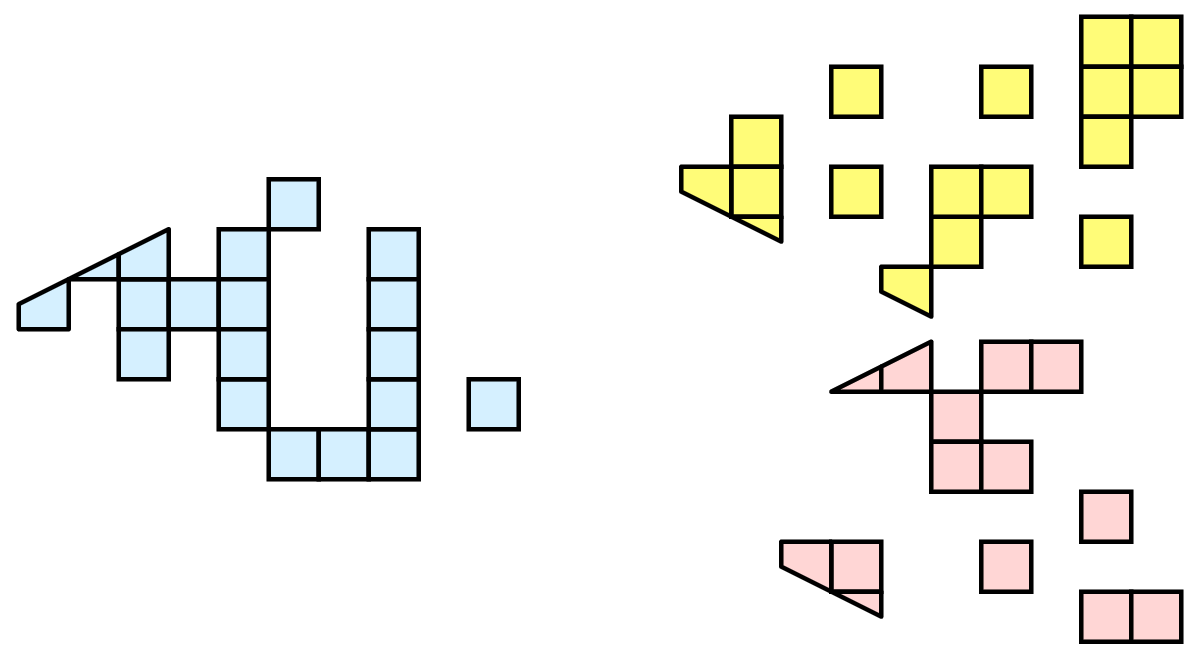
ランダム・パーティショニングには、いくつかの良い特徴があります。作成が簡単で、負荷分散に優しい。しかし、ゴーストセルに関しては深刻な問題が存在する。
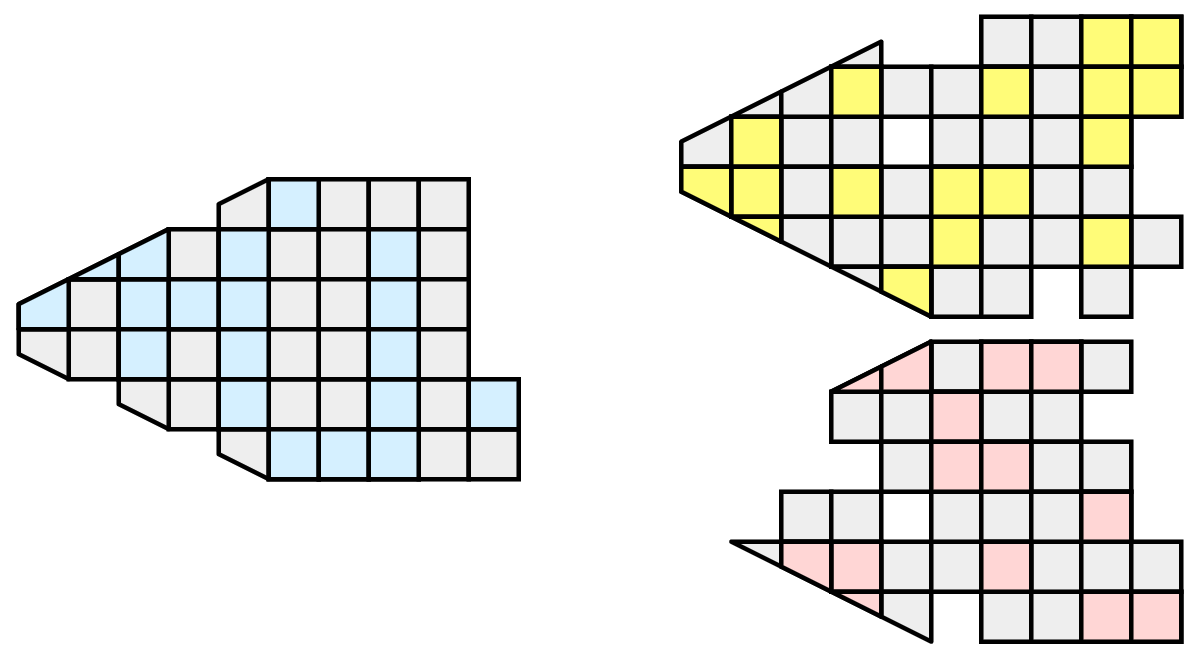
この例では、1レベルのゴーストセルが、すべてのプロセスでデータセット全体をほぼ再現していることがわかります。このように、並列処理で持っていた利点は取り除かれています。ゴーストセルは非常に頻繁に使用されるため、ParaView ではランダムパーティショニングは使用されていません。
4.7.4. D3 Filter
前節では、並列可視化におけるロードバランシングとゴーストレベルの重要性について説明しました。本節では、それを実現するための方法を説明します。
構造データ(Image Data, rectilinear grid, structured grid)を読み込む場合、ロードバランシングとゴーストセルは ParaView によって自動的に処理されます。暗黙のトポロジーにより、データを空間的にまとまった塊に分割し、隣接するセルがどこにあるかを簡単に特定することができます。
非構造データ(poly data、unstructured grid)で読み込む場合は、全く別問題です。暗黙のトポロジーがなく、近傍情報も利用できません。ParaView は、データがどのようにディスクに書き込まれたかに翻弄されます。したがって、非構造データを読み込む場合、データの負荷分散がどの程度になるかは保証されません。また、データにゴーストセルが存在する可能性も低く、一部のフィルタの出力が不正確になる可能性があります。
幸いなことに、ParaView には、非構造データのバランスをとり、ゴーストセルを作成するフィルタがあります。このフィルタはD3(distributed data decompositionの略)と呼ばれています。D3の使い方は簡単で、フィルタ(Filters → Alphabetical → D3内にあります)を分割したいデータに貼り付けるだけです。
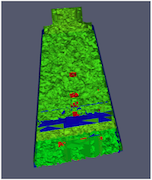
|
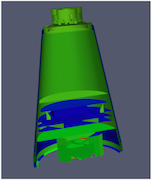
|
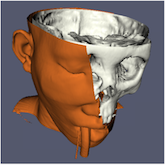
D3の最も一般的な使用例は、非構造グリッドリーダーに直接接続することです。入力データの負荷分散がいかにうまくいっていても、後続のフィルタが正しいデータを生成できるように、ゴーストセルを取得できることが重要です。上の例は、非構造格子に対する表面抽出フィルタのカットアウェイです。左側では、ゴーストセルを見逃しているため、不適切に抽出された顔が多数あることがわかる。右側では、まずD3フィルタを使ってこの問題を解決しています。
4.7.5. Ghost Cells Generator Filter
多くの場合、D3フィルタに代わるより良い方法として、ゴーストレベルジェネレーターがあります。このフィルタは、入力の非構造格子データがすでに空間的にコヒーレントな領域に分割されていることを仮定しているので、D3フィルタよりも効率的です。シミュレーションもコヒーレンスの恩恵を受けるので、これは一般的に安全な仮定です。このため,このフィルタはメッシュの外殻とその近傍のセルにのみ関係し,内部のデータの大部分は考慮しませんし,転送もしません.
4.8. アドバイス
4.8.1. ジョブサイズとデータサイズのマッチング
ParaViewサーバーのコア数はいくつにすべきでしょうか? これは、多くの重要な影響を持つ一般的な質問です。また、非常に難しい問題でもあります。その答えは、各プロセッサがどのようなハードウェアを持っているか、処理されるデータの量、処理されるデータの種類、実行される可視化操作の種類、そしてあなた自身の忍耐力など、さまざまな要因に依存します。
そのため、明確な答えがあるわけではありません。しかし、いくつかの経験則があります。
構造データを読み込む場合 (image data, rectilinear grid, structured grid)、2,000万セルあたり最低1コアを確保するようにしてください。コアに余裕がある場合は、500万~1000万セルに1コア程度で十分な場合が多いです。
非構造データを読み込む場合 (poly data, unstructured grid)、100万セルあたり最低1コアを確保するようにしてください。コアに余裕がある場合は、25~50万セルに1コア程度で十分です。
As stated before, these are just rules of thumb, not absolutes. You should always try to experiment to gauge what your core to data size should be. And, of course, there will always be times when the data you want to load will stretch the limit of the resources you have available. When this happens, you will want to make sure that you avoid data explosion and that you cull your data quickly.
4.8.2. データの爆発を防ぐ
ParaView が提示するパイプラインモデルは、探索的な可視化には非常に便利です。コンポーネント間のゆるやかな結合は、ユニークな可視化を構築するための非常に柔軟なフレームワークを提供し、パイプライン構造は、迅速かつ容易にパラメータを微調整することを可能にします。
このカップリングの欠点は、メモリフットプリントが大きくなる可能性があることです。このパイプラインの各ステージは、データの独自のコピーを維持します。可能な限り、ParaView はデータの 浅いコピー を実行し、パイプラインの異なるステージがメモリ内の同じデータブロックを指すようにします。しかし、新しいデータを作成したり、データの値やトポロジーを変更するようなフィルタは、その結果に対して新しいメモリを割り当てる必要があります。もし、ParaView が非常に大きなメッシュをフィルタリングしている場合、フィルタの不適切な使用はすぐに利用可能なすべてのメモリを枯渇させる可能性があります。したがって、大規模なデータセットを可視化する場合、フィルタのメモリ要件を理解することが重要です。
以下のアドバイスは、非常に大量のデータを扱い、残りの利用可能なメモリが少ない場合のみ を意図していることに留意してください。メモリ不足の恐れがない場合は、以下のアドバイスはすべて無視してください。
構造データを扱う場合、どのようなフィルタがデータを非構造データに変えるかを知っておくことは絶対に重要です。非構造データは構造データよりもセルあたりのメモリ使用量が多く、トポロジーを明示的に書き出さなければならないからです。ParaView には、何らかの方法でトポロジーを変更するフィルタがたくさんあり、これらのフィルタはデータを非構造格子として書き出します。以下のフィルタは、入力とほぼ等しい新しい非構造トポロジーを出力に書き出す。これらのフィルタは構造データには決して使わず、非構造データにも注意深く使われるべきです。
Append Datasets
Append Geometry
Clean
Clean to Grid
Connectivity
D3
Delaunay 2D/3D
Extract Edges
Linear Extrusion
Loop Subdivision
Reflect
Rotational Extrusion
Shrink
Smooth
Subdivide
Tessellate
Tetrahedralize
Triangle Strips
Triangulate
技術的には、リボンフィルタとチューブフィルタがこのリストに入るはずです。しかし、これらはポリデータ中の1次元セルに対してのみ作用するため、入力データは通常小さく、あまり気にする必要はありません。
この類似のフィルタも非構造格子を出力しますが、このデータの一部を削減する傾向があります。しかし、このデータ削減は非構造データへの変換のオーバーヘッドより小さいことが多いので注意が必要です。また、削減のバランスも悪いことが多いです。1つのプロセスで1つもセルが失われないこともありえます(しばしばありえます)。したがって、これらのフィルタは非構造データには注意して使用し、構造データには細心の注意を払って使用する必要があります。
Clip

Decimate
Extract Cells by Region
Extract Selection

Quadric Clustering
Threshold

前のリストの項目と同様に、Extract Subset  は構造データセットに対してデータ削減を実行しますが、構造データセットを出力することもできます。そのため、新しいデータの作成に関する警告はまだ適用されますが、非構造格子への変換を心配する必要はありません。
は構造データセットに対してデータ削減を実行しますが、構造データセットを出力することもできます。そのため、新しいデータの作成に関する警告はまだ適用されますが、非構造格子への変換を心配する必要はありません。
この次のフィルタも非構造データを出力しますが、データの次元を縮小して(例えば3Dから2D)、より小さな出力にします。したがって、これらのフィルタは通常、非構造データに対しては安全に使用でき、構造データに対しては軽い注意が必要なだけです。
Cell Centers
Contour

Extract CTH Parts
Extract Surface
Feature Edges
Mask Points
Outline (curvilinear)
Slice

Stream Tracer

これらのフィルタは、データの接続性を全く変更しません。それどころか、データにフィールド配列を追加するだけです。既存のデータはすべて浅くコピーされます。これらのフィルタは通常、すべてのデータに対して安全に使用することができます。
Block Scalars
Calculator

Cell Data to Point Data
Curvature
Elevation
Generate Surface Normals
Gradient
Level Scalars
Median
Mesh Quality
Octree Depth Limit
Octree Depth Scalars
Point Data to Cell Data
Process Id Scalars
Python Calculator
Random Vectors
Resample with dataset
Surface Flow
Surface Vectors
Texture Map to...
Transform
Warp (scalar)
Warp (vector)

この最後のフィルタ群は、出力にデータを追加しないか(結果的にすべてのデータが浅くコピーされる)、追加するデータが一般に入力のサイズに依存しないものです。これらは、どんな状況でも追加してもほとんど安全です(ただし、多くの時間がかかるかもしれません)。
Annotate Time
Append Attributes
Extract Block
Extract Level

Glyph

Group Datasets

Histogram
Integrate Variables
Normal Glyphs
Outline
Outline Corners
Plot Global Variables Over Time
Plot Over Line

Plot Selection Over Time

Probe Location

Temporal Shift Scale
Temporal Snap-to-Time-Steps
Temporal Statistics
これまでのどのクラスにもうまく当てはまらない、特殊なケースのフィルタがいくつかあります。いくつかのフィルタ、現在のところ Temporal Interpolator と Particle Tracer は、データが時間とともにどのように変化するかに基づいて計算を実行します。したがって、これらのフィルタは、2つ以上の時間のインスタンスのデータをロードする必要があり、メモリに必要なデータ量が2倍以上になる可能性があります。Temporal Cacheフィルタも、複数の時間インスタンスのデータを保持することになる。また、時間的統計や時間的にプロットするフィルタなどの時間的フィルタの中には、ディスクからすべてのデータを繰り返しロードする必要がある場合があることに留意してください。そのため、余分なメモリを必要としないにもかかわらず、非現実的なほど長い時間がかかることがあります。
プログラマブル・フィルタ  も分類不可能な特殊なケースです。このフィルタはプログラムされたことは何でもするので、これらのカテゴリのどれかに分類される可能性があります。
も分類不可能な特殊なケースです。このフィルタはプログラムされたことは何でもするので、これらのカテゴリのどれかに分類される可能性があります。
4.8.3. Culling Data
大規模なデータを扱う場合、可能な限りデータを切り出すのが最善であることは明らかで、早いほうが良いでしょう。ほとんどの大規模データは3Dジオメトリとして始まり、目的のジオメトリはサーフェスであることが多い。サーフェスは通常、その元となるボリュームよりもはるかに小さいメモリフットプリントを持っているため、すぐにサーフェスに変換するのがベストです。一度変換してしまえば、他のフィルタを比較的安全に適用することができます。
非常に一般的な可視化操作として、Contour フィルタを使用してボリュームから等値面を抽出することがあります。Contour フィルタは通常その入力よりもずっと小さな形状を出力します。従って、Contour フィルタを使うのであれば、早い段階で適用する必要があります。Contour フィルタのパラメータを設定する際には注意が必要で、大量のデータを生成してしまう可能性があります。等値面を多く指定した場合、明らかにこのようなことが起こります。また、等値面値の周辺にノイズのような高い周波数があると、大きく不規則な面が形成されることがあります。
ボリュームの内部を覗くもう一つの方法は、そのボリュームに対してスライス を実行することです。スライス フィルタは、ボリュームを平面で交差させ、平面が交差するボリュームのデータを見ることができます。大規模なデータセットで興味深い特徴の相対的な位置がわかっている場合、スライスはそれを表示するのに良い方法です。
データについてほとんど a-priori 知識がなく、完全なデータセットのためのメモリと処理時間を支払うことなくデータを探索したい場合、データをサブサンプルするためにExtract Subset フィルタを使用することができます。サブサンプルされたデータは、元のデータよりも劇的に小さくすることができ、それでも十分に負荷分散されているはずです。もちろん、サブサンプリングが小さな特徴を見逃してしまう可能性があること、また、一度特徴を見つけたら、フルデータセットに戻って可視化する必要があることに注意してください。
また、ボリュームのサブセットを抽出することができるいくつかの機能があります。Clip 、Threshold 、Extract Selection 、Extract Subset はすべてある基準に基づいてセルを抽出することが可能です。しかし、抽出されたセルはほとんどバランスが取れていないことに注意してください;いくつかのプロセスではセルが除去されていないことが予想されます。また、Extract Subset を除くこれらのフィルタはすべて、構造データ形式を非構造格子形式に変換します。したがって、抽出されたセルがソースデータよりも少なくとも1桁少ない場合を除き、これらのフィルタを使用すべきではありません。
可能な限り、3Dデータを抽出するフィルタの使用を、2D表面を抽出するフィルタに置き換えてください。例えば、データを通る平面に興味がある場合は、Clip フィルタではなく、Slice フィルタを使用します。特定の範囲の値を含むセルの領域の位置を知りたい場合は、Threshold フィルタですべてのセルを抽出するのではなく、Contour フィルタを使用して範囲の端にサーフェスを生成することを検討してください。フィルタの置き換えは、下流のフィルタに影響を与える可能性があることに注意してください。例えば、Threshold の後に Histogram フィルタを実行すると、ほぼ同等の Contour フィルタの後に実行した場合とは全く異なる効果が得られます。
4.8.4. Downsampling
ダウンサンプリングは、非常に大きなデータにもよく役に立ちます。例えば、Extract Subset フィルタは、i, j, k 軸に沿ったストライドサンプルを取ることを簡略化して、Structured DataSets のサイズを縮小する。
非構造格子の場合、Quadric Clusteringフィルタは、格子のセル内の頂点を平均化することにより、非構造データを類似の外観を持つより小さなデータセットにダウンサンプリングします。ParaView は、次節で説明するように、カメラとの対話の間にこのアルゴリズムを表示パイプラインに注入します。
しかし、場合によっては、非構造データよりも構造データを扱う方が効果的なことがあります。特に、構造データのボリュームレンダリングアルゴリズムは、通常、はるかに高速です。一般に、構造データ形式は非常にコンパクトで、生のデータ値にほとんどオーバーヘッドを加えません。非構造データ形式では、各頂点に12バイトのメモリストレージが必要で、セルとポイントアライメント値の通常のストレージの他に、各セルを定義するために少なくとも8バイトのストレージが必要です。構造タイプは、比較のために、頂点とセルのセット全体を表現するために合計36バイトを使用します。
幸いなことに、リサンプル画像化フィルタを使えば非構造から構造へ簡単に変換できます。入力のセルの大きさがあまり大きくなく、一定の大きさのボクセルでうまく近似できる場合、これは非常に効果的です。このフィルタは、内部でDIY2ブロック並列通信・計算ライブラリを利用して、並列ノード間の通信とデータ転送を行っています。
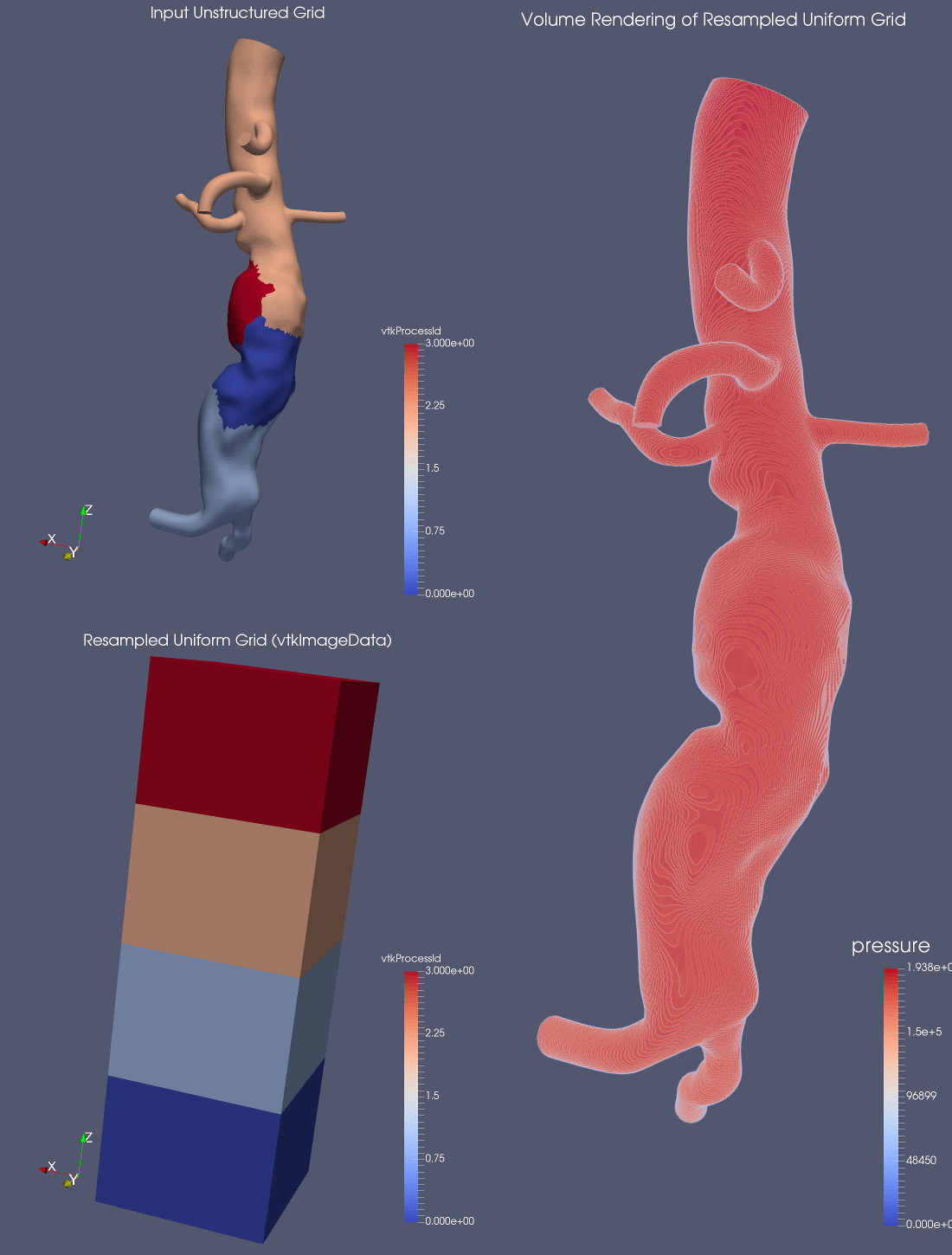
Resample With DataSet というフィルタがあり、これはソースと入力オブジェクトを受け取り、ソースから入力に値をリサンプルします(通常のグリッドである必要はありません)。これも DIY2 を使用します。これは、特定の形状のオブジェクトに新しい値を割り当てるために使用されます。
4.9. 並列レンダリングの詳細
レンダリングは、データに基づいて目に見える画像を合成するプロセスです。データを効果的に操作できるかどうかは、レンダリングの速度に大きく依存します。コンピュータゲーム市場に後押しされた3Dハードウェアアクセラレーションの進歩により、中価格帯のコンピュータでも3Dを高速にレンダリングすることができるようになりました。しかし、当然のことながら、レンダリングの速度はレンダリングするデータ量に比例します。データが大きくなれば、当然、レンダリング処理も遅くなります。
可視化セッションをインタラクティブに維持するために、ParaView は必要に応じて自動的に反転される2つのレンダリングモードをサポートしています。最初のモードである still render では、データは最高レベルの詳細さでレンダリングされます。このレンダリングモードでは、すべてのデータが正確に表現されます。2つ目のモードである Interactive render では、正確さよりもスピードが優先されます。このレンダリングモードでは、データサイズに関係なく、迅速なレンダリングレートを提供するよう努めます。
マウスによる回転、パン、ズームなど、3Dビューとインタラクションしている間、ParaView はインタラクティブ・レンダリングを使用します。これは、インタラクション中はこれらの機能を使用するために高いフレームレートが必要であり、インタラクションが発生している間は各フレームが直ちに新しいレンダリングに置き換えられるため、このモードでは細かい部分があまり重要でないためです。3Dビューのインタラクションが行われていないときは、ParaView は静止レンダリングを使用し、データの完全な詳細を学習することができます。3Dビューでマウスをドラッグしてデータを移動させると、マウスを動かしている間はおおよそのレンダリングが表示されますが、マウスボタンを離すとすぐに完全な詳細が表示されます。
インタラクティブレンダリングは、スピードと正確さの妥協点です。そのため、レンダリングパラメータの多くは、低レベルのディテールをいつ、どのように使用するかに関係します。
4.9.1. レンダリングの基本設定
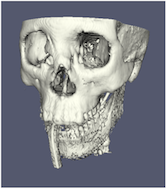
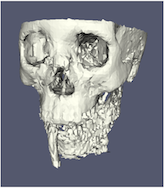
最も重要なレンダリングオプションに、LOD パラメータがあります。インタラクティブレンダリングでは、ジオメトリをより低い level of detail (LOD) 、より少ないポリゴンで近似したジオメトリに置き換えることができます。
|
|

|
幾何学的近似の解像度を制御することができます。左の画像はフル解像度、中央の画像はインタラクティブレンダリングのためのデフォルトのデシメーション、そして右の画像は ParaView の最大デシメーション設定である。
3Dレンダリングのパラメータは、メニューの Edit → Settings (Macでは ParaView → Preferences) からアクセスできる設定ダイアログボックスにあります。ダイアログのレンダリングオプションは レンダリングビュー タブ内にあります。
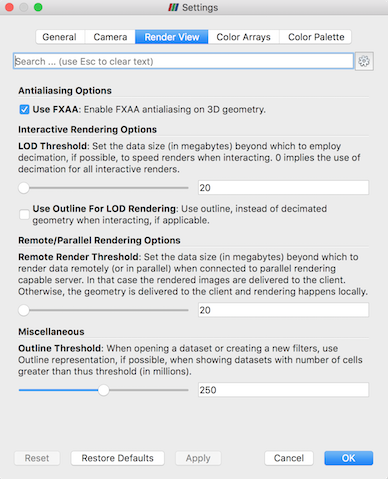
インタラクティブレンダリングのための幾何学的デシメーションに関するオプションは、インタラクティブレンダリングオプションというラベルのついたセクションにあります。これらのオプションのいくつかは高度なものとみなされているので、アクセスするには  ボタンを使って高度なオプションをオンにするか、ダイアログ上部の編集ボックスを使ってオプションを検索する必要があります。インタラクティブレンダリングオプションには次のようなものがあります。
ボタンを使って高度なオプションをオンにするか、ダイアログ上部の編集ボックスを使ってオプションを検索する必要があります。インタラクティブレンダリングオプションには次のようなものがあります。
インタラクティブレンダリングにおいて、デシメーションされたジオメトリを使用する際のデータサイズを設定する。ジオメトリサイズがこの閾値以下であれば、ParaView は常にフルジオメトリをレンダリングします。より大きなデータを処理できる適切なグラフィックカードを持っている場合は、この値を増やします。インタラクティブレンダリングが遅すぎる場合は、この値を減らしてみてください。
デシメーションされたジオメトリがどの程度の大きさになるかを制御するファクターを設定します。このコントロールは0と1の間の値に設定されます。0は非常に少数のトライアングルを作成しますが、おそらく多くの歪みを伴います。1は、より詳細なサーフェスを作成しますが、ジオメトリは大きくなります。
インタラクティブレンダリングとスチルレンダリングの間にディレイを追加します。通常、ParaView はインタラクティブな動作が終了するとすぐに静止画レンダリングを行います(例えば、回転の後にマウスボタンを離すなど)。このオプションは、静止画レンダリングが始まる前に2つ目のインタラクションを開始する時間を与える遅延を追加することができ、静止画レンダリングが完了するまでに長い時間がかかる場合に便利です。
デシメーションされたジオメトリの代わりに、アウトラインを使用します。アウトラインは、ジオメトリのデシメーションに時間がかかりすぎる場合や、まだジオメトリが多すぎる場合に使用する代替手段です。ただし、アウトラインだけでは対話が難しくなります。
ParaView には、他にも多くのレンダリング設定があります。ここでは、ParaView をクライアントサーバーモードで実行するかどうかに関係なく、レンダリングパフォーマンスに影響を与えることができる他のいくつかの設定の概要を説明します。これらのオプションはいくつかのカテゴリーに分かれており、いくつかは高度なものとみなされています。
Geometry Mapper Options
ディスプレイリストの使用を有効または無効にします。ディスプレイリストは、グラフィックシステムによって構築された内部構造です。レンダリングを高速化できる可能性がありますが、メモリを消費する可能性もあります。
Translucent Rendering Options
深度ピーリング(Depth Peeling)の有効・無効を設定します。深度ピーリングは、半透明の表面を適切にレンダリングするために ParaView が使用する技術です。この技法では、上面がレンダリングされ、次に下面がレンダリングできるように “剥離” され、これが繰り返されます。サーフェスを透明にすると本当に遅くなる、または完全に間違ってレンダリングされる場合は、グラフィックスハードウェアが深度ピーリング拡張をうまく実装していない可能性があります。
深度ピーリングで使用する最大ピーリング回数を設定します。より多くのピールを使用すると、より複雑な深度が得られますが、より少ないピールを使用すると、より速く実行されます。半透明なジオメトリのレンダリングが遅い場合や、半透明なイメージが正しく表示されない場合は、このパラメータを調整してみてください。
Miscellaneous
非常に大きなデータセットを作成する場合、デフォルトでアウトライン表現にします。サーフェス表現では通常、サーフェスのジオメトリを抽出するために ParaView を必要とし、これには時間とメモリがかかります。この閾値を超えるサイズのデータでは、代わりにオーバーヘッドが非常に少ないアウトライン表現をデフォルトで使用します。
レンダリングパフォーマンス情報を提供する注釈を表示または非表示にします。この情報は、パフォーマンスの問題を診断するときに便利です。
これは、ParaViewのレンダリング設定の完全なリストではないことに注意してください。レンダリングパフォーマンスに大きな影響を与えない設定は省いてあります。また、クライアントとサーバーの並列レンダリングにのみ有効な設定も省きました。これについては、 4.9.3 章 で説明しています。
4.9.2. Image Level of Detail
The overhead incurred by the parallel rendering algorithms is proportional to the size of the images being generated. Also, images generated on a server must be transferred to the client, a cost that is also proportional to the image size. To help increase the frame rate during interaction, ParaView introduces a new LOD parameter that controls the size of the images.
During interaction while parallel rendering, ParaView can optionally subsample the image. That is, ParaView will reduce the resolution of the image in each dimension by a factor during interaction. Reduced images will be rendered, composited, and transferred. On the client, the image is inflated to the size of the available space in the GUI.
|
|
|

|
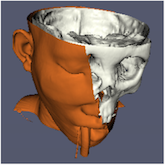
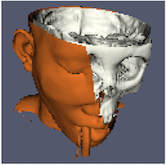
縮小画像の解像度は、寸法を分割する倍率によって制御されます。前の画像では、左の画像がフル解像度です。次の画像は、それぞれ解像度を2倍、4倍、8倍に縮小してレンダリングしたものです。
ParaView は、サーバーからクライアントへ転送する前に画像を圧縮する機能も備えています。圧縮すると、もちろん転送されるデータ量が減るので、利用できる帯域幅を最大限に活用できる。しかし、画像の圧縮と解凍にかかる時間が待ち時間に加算されます。
ParaView には、クライアントサーバーレンダリングのための3つの異なる画像圧縮アルゴリズムが含まれています。最も古いものは、Sequential Unified Image Run Transferの頭文字をとって Squirt と呼ばれるカスタムアルゴリズムです。Squirtはランレングスエンコーディング圧縮で、色深度を減らしてランレングスを長くします。2番目のアルゴリズムは、Lempel-Zivアルゴリズムのバリエーションを実装した圧縮ライブラリ Zlib を使用しています。Zlibは通常、Squirtよりも優れた圧縮を提供しますが、実行に時間がかかり、そのため待ち時間が増えます。最近追加されたのは、高速な圧縮と解凍のために調整された LZ4 アルゴリズムです。
4.9.3. Parallel Render Parameters
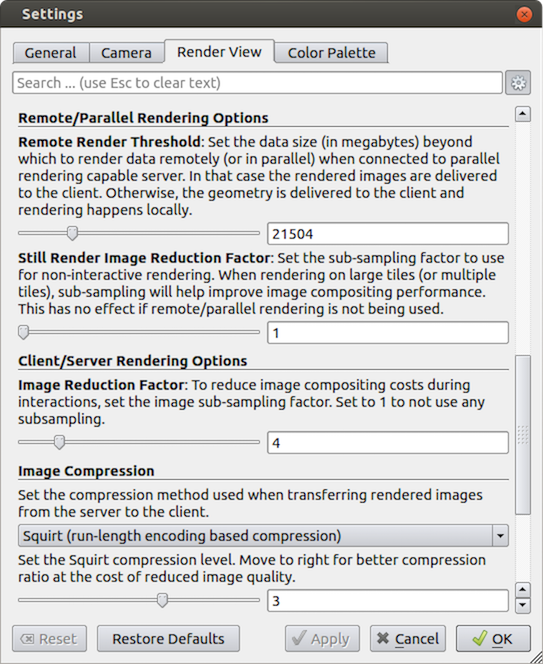
他の3Dレンダリングパラメータと同様に、パラレルレンダリングパラメータは設定ダイアログボックスにあり、メニューの Edit → Settings (Mac では ParaView → Preferences) でアクセスできます。ダイアログの並列レンダリングオプションは、レンダリングビュータブにあります( 4.9.1 章 で説明されているような他のいくつかのレンダリングオプションと混在しています)。並列およびクライアント・サーバーのオプションはいくつかのカテゴリに分かれており、いくつかは上級者向けとされています。
Remote/Parallel Rendering Options
リモートで並列レンダリングするか、ローカルでレンダリングするか、そのデータサイズを設定します。ジオメトリがこの閾値を超えている場合(そして ParaView がリモートサーバーに接続されている場合)、データはリモートで並列レンダリングされ、イメージはクライアントに送り返されます。ジオメトリがこの閾値を下回っている場合、ジオメトリはクライアントに送り返され、画像はクライアント上でローカルにレンダリングされます。
静止画(非インタラクティブ)レンダリング時のサブサンプリング係数を設定します。大型ディスプレイの中には、本当に必要以上の解像度を持つものがあるので、このサブサンプリングによって、表示されるすべての画像の解像度が下がります。
Client/Server Rendering Options
インタラクティブサブサンプリング係数を設定します。並列レンダリングのオーバーヘッドは、生成される画像のサイズに比例します。したがって、画像のサブサンプリング率を指定することで、インタラクティブレンダリングを高速化することができます。このボックスにチェックを入れると、インタラクティブレンダリングはより小さな画像を作成し、表示時に拡大表示されます。このパラメータは、インタラクティブレンダリング時のみ使用されます。
Image Compression
サーバーからクライアントへ画像を送信する前に、オプションで3つの圧縮アルゴリズムのうち1つを使用して圧縮することができます。Squirt、Zlib、LZ4 です。圧縮をより効果的にするために、各アルゴリズムには1つ以上の調整可能なパラメータがあり、動作や圧縮の目標レベルをカスタマイズすることができます。
一般的なネットワークの種類に応じて、推奨される画像圧縮のプリセットが提供されています。最適な画像圧縮オプションを選択する場合は、接続に最も適したプリセットから始めてみてください。
4.9.4. Parameters for Large Data
デフォルトのレンダリングパラメーターは、ほとんどのユーザーにとって適切なものです。しかし、非常に大きなデータを扱う場合は、レンダリングパラメータを調整することが有効です。最適なパラメータは、データと ParaView が動作しているハードウェアによって異なりますが、以下にいくつかのアドバイスを示しますので、従ってください。
ディスプレイリストをオフにしてみてください。このオプションをオフにすると、グラフィックシステムが特別なレンダリング構造を構築するのを防ぎます。グラフィックハードウェアがある場合、これらのレンダリング構造は GPU に十分な速さで給電するために重要です。しかし、GPU がない場合、これらのレンダリング構造はあまり役 に立ちません。
特定のデータセットの最初のインタラクティブレンダリングの前に長い一時停止がある場合、それは間引きされたジオメトリの作成である可能性があります。インタラクションでは、間引きされたジオメトリではなくアウトラインを使用してみてください。また、間引き係数を0に下げて、より小さいジオメトリを作成することもできます。
大きなジオメトリをクライアントに送り返さないようにします。リモートレンダリングは、サーバー全体のパワーを使って画像をレンダリングし、クライアントに送信します。リモートレンダリングがオフの場合、ジオメトリはクライアントに送り返されます。大きなデータがある場合、データを送信するよりも画像を送信する方が常に高速です(ただし、ネットワークのレイテンシーが高い場合、インタラクティブなフレームレートではこれが問題になる可能性があります)。
必要に応じて、クライアント・サーバー・レンダリングのインタラクティブ画像のサブサンプリングを調整します。画像合成が遅い場合、クライアントとサーバー間の接続が低帯域の場合、または非常に大きな画像をレンダリングする場合、高いサブサンプルレートはインタラクティブレンダリングのパフォーマンスを大幅に改善することができます。
画像圧縮がオンになっていることを確認してください。デスクトップ配信のパフォーマンスに多大な影響を与え、インタラクティブレンダリング時にのみ発生するアーティファクトはごくわずかです。低帯域幅の接続では、Squirt圧縮の代わりにZlib又はLZ4を使用してみてください。Zlibはより小さな画像を作成しますが、その代償として圧縮/解凍にかかる時間が長くなります。
ネットワーク接続のレイテンシーが高い場合は、インタラクション中にリモートレンダリングを行わないようにパラメータを調整します。この場合、リモートレンダリングの閾値を少し上げてみると、インタラクティブレンダリングにアウトラインを使うのが効果的な場所です。
静止画(非インタラクティブ)のレンダリングが遅い場合は、インタラクティブと静止画のレンダリング間の遅延をオンにして、不要なレンダリングを回避してみてください。
4.10. Catalyst
小規模なデータであれば、シリアルモードで ParaView GUI を実行しても問題ないでしょう。大規模データでは、対話的な並列可視化が非常に有効です。非常に大規模なデータでは、並列ジョブが起動するまでのバッチシステムのキュー待ち時間や、対話型ジョブのサイズと時間を制限するシステムポリシーなどの実用的な懸念があるため、バッチモードの並列処理がより効果的です。
比較的低速のディスクでは、シミュレーションによってランタイムに保存できるデータのサイズが制限されるため、極端なスケールの可視化にはバッチモードでさえ実用的でなくなり始めています。この分野では、ParaView の Catalyst 構成が、in situ 分析および可視化ライブラリとして推奨されます。
Catalyst は、ParaViewの並列サーバーフレームワークの一部または全部をパッケージ化した可視化フレームワークで、任意のシミュレーションコードにリンクして呼び出すことができます。低速なIOシステムは、シミュレーションコードのデータ構造が ParaView によって翻訳されるか、理想的にはまだRAMにある間に直接再利用されるアダプタメカニズムによって、ほとんどバイパスされます。
Catalystでは、フル解像度のシミュレーション製品は、ディスクに保存して後でロードし直すのではなく、メモリに保存されます。シミュレーションの進行に伴い、定期的に ParaView を呼び出します。このようにして、通常であればポスト処理中に生成される、より小さな派生データセット、画像、プロットなどを、より長い時間、ループ内の人間の手によって、即座に生成することができるのです。
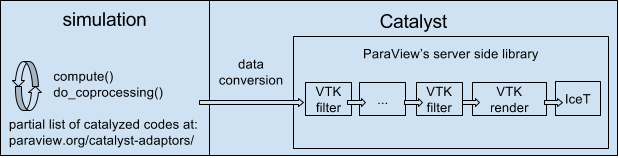
詳細は ParaView Catalyst User's Guide で説明していますが、Catalystを使用するためには2つの要素があります。1つ目は、シミュレーションのCatalyzeです。ソフトウェア開発者は、シミュレーションにCatalystをコンパイルし、いくつかの(通常は3つの)関数呼び出しを追加し、シミュレーション自身の内部データ構造からVTKデータセットを生成するコードを持つアダプタ・テンプレートを作成します。
シミュレーションが Catalyzed された後、日々のユーザーは与えられたデータに対して ParaView が何をすべきかを定義する必要があります。Catalystはデータ抽出、画像、統計量などを作成することができます。ランタイム効率を最大化するために、Pythonや低レベルのFortran、C、C++コーディングで作成することもできますが、次の演習で示すように記録されたCatalystスクリプトで行う方がより柔軟で便利です。
Catalystスクリプトでは、シミュレーション入力デッキは可視化パイプラインを定義するPythonファイルを参照します。スクリプトは、ParaView バッチスクリプトが行うほぼすべてのことを行うことができ、通常、ParaView GUIからヘルプを得て作成されます。スクリプトを作成するには、代表的なデータセットをロードし、パイプラインを作成し、パイプラインへの入力と出力のセットを指定し、Pythonファイルを保存するだけである。Catalyst スクリプトは、記録された Python トレースに非常によく似ています。
入力と出力を定義するためのユーザーインターフェイスは、Catalyst Script Generatorプラグイン内にあります。最後の演習では、小さな例でデモを行います。
練習 4.4 (Catalyst)
ParaView バイナリ、および ParaView ソースツリーのPythonFullExampleコードを使ってCatalystワークフローをデモします。PythonFullExampleは、numpyとmpi4pyを使用して、時間の経過とともに規則的なグリッドを更新する模擬シミュレーションです。このサンプルは4つのファイルから構成されています。まず、これらを開いて読んでみてください。
計算カーネルはfedatastructures.pyにあります。このコードを見てみると、特に ParaView に依存しているわけではなく、単にnumpyとmpi4pyと並列に構造格子を構成していることがわかります。
fedatastructures.pyより:
def Update(self, time):
self.Velocity =
numpy.zeros((self.Grid.GetNumberOfPoints(), 3))
self.Velocity = self.Velocity + time
self.Pressure = numpy.zeros(self.Grid.GetNumberOfCells())
メインループはfedriver.pyに記載されています。doCoprocessing変数がfalseの場合、単純なループに戻り、シミュレーションを実行し、メモリ内の配列を時間経過とともに更新します。変数がtrueの場合、Catalystライブラリはinitialize(), coprocess(), finalize()の3つの関数コールで実行されます。
fedriver.pyより:
import numpy
import sys
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
import fedatastructures
grid = fedatastructures.GridClass([10, 12, 10], [2, 2, 2])
attributes = fedatastructures.AttributesClass(grid)
doCoprocessing = True
if doCoprocessing:
import coprocessor
coprocessor.initialize()
coprocessor.addscript("cpscript.py")
for i in range(100):
attributes.Update(i)
if doCoprocessing:
import coprocessor
coprocessor.coprocess(i, i, grid, attributes)
if doCoprocessing:
import coprocessor
coprocessor.finalize()
fedriver.py と fedatastructures.py はシミュレーションのコードです。Catalystの部分は、coprocessor.pyにある汎用アダプタのコードと、cpscript.pyにあるパイプラインの定義で構成されています。coprocessor.pyでは、特に、coprocess関数がdataDescriptionデータ構造を生成して、fedatastructureのコンテンツを ParaView に渡しているところに注目してください。コプロセッサーはまた、パイプライン定義ファイルをaddscript()コールで取り込みます。
coprocessing.pyより:
if coProcessor.RequestDataDescription(dataDescription):
import fedatastructures
imageData = vtk.vtkImageData()
imageData.SetExtent(\
grid.XStartPoint, grid.XEndPoint, \
0, grid.NumberOfYPoints-1, \
0, grid.NumberOfZPoints-1)
imageData.SetSpacing(grid.Spacing)
velocity = paraview.numpy_support.numpy_to_vtk(attributes.Velocity)
velocity.SetName("velocity")
imageData.GetPointData().AddArray(velocity)
pressure = numpy_support.numpy_to_vtk(attributes.Pressure)
pressure.SetName("pressure")
imageData.GetCellData().AddArray(pressure)
この例のスタートスクリプトはcpscript.pyと呼ばれています。これは単に与えられた入力を ParaView GUIが容易に理解できるフォーマットで保存するだけです。PipelineClassの内部は、基本的にファイルではなくアダプタのdatadescriptionクラスを入力とする ParaView バッチスクリプトになっています。
cpscript.pyより:
class Pipeline:
filename_6_pvti = \
coprocessor.CreateProducer( datadescription, "input" )
# create a new 'Parallel ImageData Writer'
imageDataWriter1 = \
servermanager.writers.XMLPImageDataWriter(Input=filename_6_pvti)
# register the writer with coprocessor
# and provide it with information such as the filename to use,
# how frequently to write the data, etc.
coprocessor.RegisterWriter(imageDataWriter1, \
filename="fullgrid_%t.pvti", freq=100)
Slice1 = Slice( \
Input=filename_6_pvti, guiName="Slice1", \
Crinkleslice=0, SliceOffsetValues=[0.0], \
Triangulatetheslice=1, SliceType="Plane" )
Slice1.SliceType.Offset = 0.0
Slice1.SliceType.Origin = [9.0, 11.0, 9.0]
Slice1.SliceType.Normal = [1.0, 0.0, 0.0]
# create a new 'Parallel PolyData Writer'
parallelPolyDataWriter1 = \
servermanager.writers.XMLPPolyDataWriter(Input=Slice1)
# register the writer with coprocessor
# and provide it with information such as the filename to use,
# how frequently to write the data, etc.
coprocessor.RegisterWriter(\
parallelPolyDataWriter1, filename='slice_%t.pvtp', freq=10)
return Pipeline()
では、シミュレーションコードを実行して、データを作成してみましょう。
Macでは:
/Applications/ParaView-x.x.x.app/Contents/MacOS/mpiexec -np 2 /Applications/ParaView-x.x.x.app/Contents/bin/pvbatch –symmetric fedriver.pyLinuxでは:
/usr/local/lib/paraview-x.x.x/mpiexec -np 2 /usr/local/bin/pvbatch –symmetric fedriver.pyWindowsでは:
mpiexec -np 2 "C:/Program Files/ParaView x.x.x/bin/pvbatch" –symmetric fedriver.py
このサンプルは実行され、いくつかのファイルを生成します。その中のfullgrid_0.pvtiはシミュレーションのフル出力の生ダンプです。Catalystの出力をカスタマイズするために使用します。
まず、ファイルを ParaView GUI で開き、検査します。これは圧力と速度の2つの変数を持つ非常に単純な構造格子であることがわかります。ここで、パイプラインにFile → Extract Subsetフィルタを挿入して、簡単ですが便利な処理を実演してみましょう。
次に、Export Inspector を使用して、Catalyst が実行時に生成するファイル セットを宣言してみましょう。これから説明するように、ParaView GUI は、ParaView で構築された可視化の現在の状態をキャプチャすることによって Catalyst スクリプトを生成することが可能です。しかし、この状態にはファイルの作成は含まれません。これは通常、File → Save Data または File → Save Screenshot アクションによって対話型セッションで行われます。
ParaView 5.6以降、Catalystのデータ製品を定義する場所としてエクスポートインスペクターが使用されています。Catalystメニューの Export Inspectorをクリックすると、このパネルが表示されます。デフォルトでは、このパネルはプロパティパネルの近くの新しいタブに表示されます。必要に応じて選択し、最前面に表示させます。
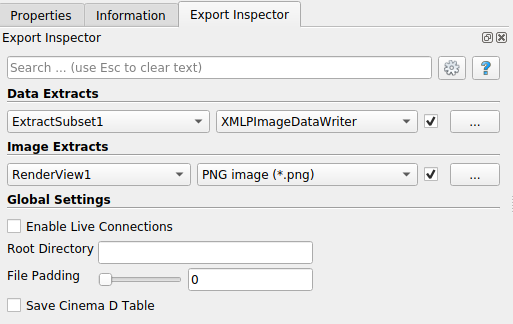
上部のData Extractsセクションで、可視化パイプライン内の現在アクティブな要素にライターをアタッチすることができます。パイプラインブラウザで ExtractSubset1 が選択されていることを確認し、Data Extractsでこのフィルタ名の右側にあるファイルフォーマットプルダウンからXMLPImageDataWriterを選択します。この特定のデータエクスポートを実行時に Catalyst で実行することを確認するには、ファイル形式の右側にあるチェックボックスをクリックします。
ライターのデフォルト設定を変更したい場合は、チェックボックスの右側にある ... ラベルの付いた設定ボタンをクリックします。Save Data Optionsダイアログが表示され、圧縮レベル、Catalystがファイルを生成する頻度、ファイル名などを制御することができます。デフォルトのファイル名は、生成フィルタの名前、タイムステップ、ファイルフォーマットの拡張子から構成されています。“ExtractSubset1_%t.pvti” から “smallgrid_%t.pvti” に変更してみましょう。ここで、“%t” はシミュレーション実行時のイテレーション番号に置き換わります。このスクリプトを使用してシミュレーションを実行すると、フルグリッドではなく、サブサンプルの結果が得られます。
シミュレーション実行にレンダリングイメージを追加するには、エクスポートインスペクタのイメージエクストラクトセクションで設定します。データ抽出と同様に、ここでは現在アクティブなビューの出力を設定します。“RenderView1” がアクティブであることを確認し、このビューのpngダンプを有効にするチェックボックスを押してください。
可視化セッションを Catalyst スクリプトの形式で保存するには、Catalyst → Catalyst スクリプトの書き出し をクリックします。エクスポートインスペクターで選択した内容は、残りの ParaView 状態と一緒に保存されるため、File → Save State を実行すると、後から設定を簡単に変更することができることに注意してください。
最後に ParaView を終了し、シミュレーションを再実行します。生成されるファイルには、各タイムステップのスクリーンキャプチャ用のpngファイルと、各タイムステップのExtract Subsetフィルタの出力に対応するvtiファイルが含まれています。この作業を繰り返すだけで、フィルタやビューを追加し、あらゆるタイプのシミュレーション用データジェネレーターをセットアップすることができます。
これはCatalystを使用するための1つのインターフェイスに過ぎないことに注意してください。シミュレーションのユーザーが ParaView や Python を使いこなせない場合、シミュレーションの開発者は Python に頼ることなく、定義済みでパラメータ化されたパイプラインでシミュレーション・コードをインストルメントすることが可能です。また、より大きな ParaView のコードベースのごく一部で構成される最小限のCatalystエディションを作成することも可能です。
ParaView 自体もそうですが、Catalystは急速に進化しています。ここで説明したものよりも、さらに高度な分派がすでにあります。一つはライブデータ機能で、ParaView クライアントを実行中のCatalyzedシミュレーションに接続し、その進行状況を時々チェックし、限定的な計算ステアリングとデバッギングを行うことができるものです。もう一つはCinemaで、これは自動的に生成されたシミュレーション結果をデータベースで整理して繰延可視化するための画像ベースのフレームワークです。これらに関する情報は、ParaView のメーリングリストとウェブサイトを参照してください。